Discovery of Intentional Self-Harm Patterns from Suicide and Self-Harm Surveillance Reports
Article information

Abstract
Objectives
The purpose of this study was to identify patterns of self-harm risk factors from suicide and self-harm surveillance reports in Thailand.
Methods
This study analyzed data from suicide and self-harm surveillance reports submitted to Khon Kaen Rajanagarindra Psychiatric Hospital, Thailand. The process of identifying patterns of self-harm risk factors involved: data preprocessing (namely, data preparation and cleaning, missing data management using listwise deletion and expectation-maximization techniques, subgrouping factors, determining the target factors, and data correlation for learning); classifying the risk of self-harm (severe or mild) using 10-fold cross-validation with the support vector machine, random forest, multilayer perceptron, decision tree, k-nearest neighbors, and ensemble techniques; data filtering; identifying patterns of self-harm risk factors using 10-fold cross-validation with the classification and regression trees (CART) technique; and evaluating patterns of self-harm risk factors.
Results
The random forest technique was most accurate for classifying the risk of self-harm, with specificity, sensitivity, and F-score of 92.84%, 93.12%, and 91.46%, respectively. The CART technique was able to identify 53 patterns of self-harm risk, consisting of 16 severe self-harm risk patterns and 37 mild self-harm risk patterns, with an accuracy of 92.85%. In addition, we discovered that the type of hospital was a new risk factor for severe self-harm.
Conclusions
The procedure presented herein could identify patterns of risk factors from self-harm and assist psychiatrists in making decisions related to self-harm among patients visiting hospitals in Thailand.
I. Introduction
According to the World Health Organization, nearly 800,000 people committed suicide in 2016, representing 1.4% of deaths worldwide [1]. Over three-quarters of these deaths occurred in low- to middle-income countries, and approximately 53,000 suicides were recorded in Thailand each year, representing the highest incidence in the Association of Southeast Asian Nations [2,3]. Due to the increasing number of people who are at risk for self-harm and commit suicide, it is vital to develop techniques for effectively monitoring patients who are at risk of self-harm.
Machine learning (ML), an application of artificial intelligence (AI), has been employed in healthcare information research to provide more rapid and accurate support for doctors’ and psychiatrists’ decisions [4]. In ML, a computer system is programmed with the ability to learn from its experiences and automatically improve. There are three main types of ML: supervised, unsupervised, and reinforcement learning. The supervised learning approach has been intensively used in healthcare informatics research [5,6].
With respect to mental wellness, ML techniques have been employed to classify suicide risk patterns. For example, Boonkwang et al. [7] classified suicidal ideation and patterns of suicidal ideation risk factors using the Iterative Dichotomiser 3 (ID3), J48, naive Bayes, and ensemble techniques. Zalar et al. [8] employed the decision tree (DT), genetic algorithm, and supplementary vector techniques to examine risk factors for attempting suicide. Edgcomb et al. [9] adapted the classification and regression trees (CART) technique to classify the risk of suicide attempts among women who had posthospital depression, bipolar disorder, and chronic psychosis. Although identifying self-harm risk patterns would be useful for psychiatrists, the main obstacle is obtaining accurate and suitable data for analysis.
Suicide and self-harm surveillance reports (RP.506S) are completed by hospitals in all 76 provinces in Thailand. The report form used for this dataset, which was designed by Khon Kaen Rajanagarindra Psychiatric Hospital with 10 versions from 2003 to the present, consists of the following data: type of hospital, region in Thailand, data source, demographic information, type of service, being hurt by others, hurt others, self-harm one or more times, self-harming methods, cause of depression, health problems, personal behavior, intervention, referring hospital type, thoughts of suicide, hospital admission, and death.
These data are reported to Khon Kaen Rajanagarindra Psychiatric Hospital, which is the center for collecting data for analysis by the Department of Mental Health in Thailand. Two types of services are provided in each visit: depression services and self-harm services. All visits were considered to have been made by patients at risk of self-harm because depressed patients are capable of self-harm, and self-harm patients are capable of repeating self-harm. Therefore, follow-up is necessary for both types of patients. Self-harm risk can be classified as severe and mild. A severe risk refers to self-harm that can lead to hospitalization or death, whereas a mild risk of self-harm is present in non-self-harm patients who may be followed up or first-time depression patients.
Therefore, the data from these surveillance reports are appropriate for determining the patterns of risk factors for self-harm. This study aimed to identify patterns of risk factors for self-harm using ML from RP.506S reports. The findings of this study will support psychiatrists’ decision-making in the self-harm risk analysis of patients.
II. Methods
1. Dataset
The dataset used in this study was retrospectively collected from suicide and self-harm surveillance reports (RP.506S) from Khon Kaen Rajanagarindra Psychiatric Hospital recorded from 2004 to 2016. The reports refer to 192,234 visits from 103,316 patients: most patients had one visit (85,399 patients), followed by patients with two visits (12,089 patients), and patients with three visits (4,384 patients). One patient made 80 visits, and on average, each patient made two visits. There were 103 factors, including: (1) type of hospital (primary care, secondary care, tertiary hospital, psychiatric hospital, and other); (2) region in Thailand (northern, northeastern, central, eastern, western, and southern); (3) data source (i.e., the source of information provided to the patient at that visit, which was recorded by staff who interviewed the patient, asked close relatives or service providers, or made observations from the outpatient department card, inpatient medical records,-or death certificates or other sources); (4) the ethnicity of patients (Thai, hill tribes, Khmer, Myanmar, Laos, China, Western, and other); (5) demographic information (gender, age, marital status, and occupation); (6) type of service (e.g., depression or self-harm); (7) depression during the visit; (8) history of injury by abuse by others; (9) history of the patient harming another person; (10) the number of self-harm times (once and more than once); (11) self-harm methods; (12) problems that cause depression or self-harm; (13) health problems; (14) personal behavior; (15) intervention; (16) the type of hospital that referred the patient; (17) hospital admission; (18) death; and (19) suicidal ideation (if the patient did not die by suicide).
2. Conceptual Framework
Figure 1 shows the conceptual framework of this study, which can be described as follows: data preprocessing, classifying self-harm risk to select the dataset and the best ML method, data filtering, identifying patterns of self-harm risk factors, and evaluating the self-harm risk patterns.
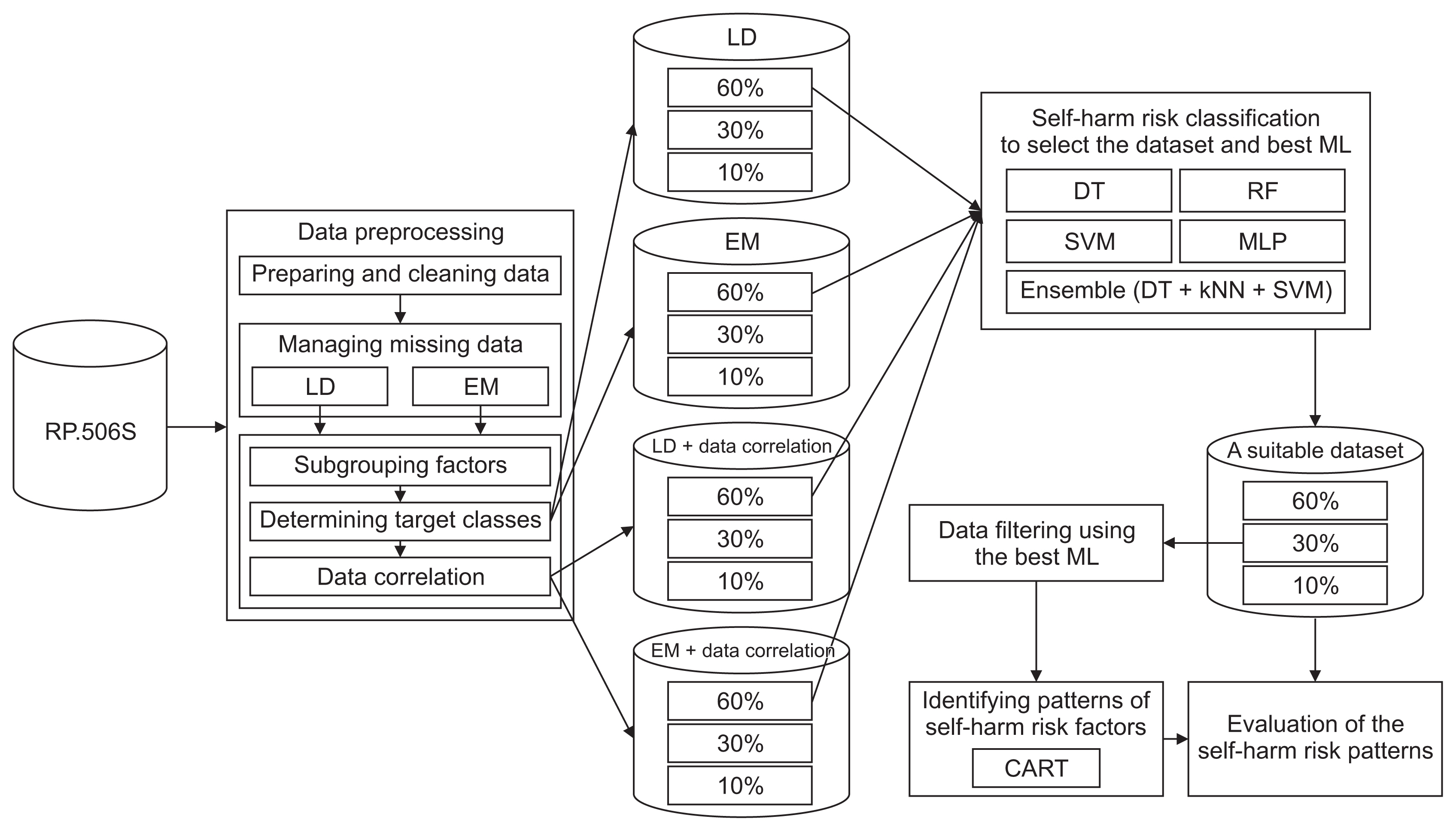
Conceptual framework of this research. LD: listwise deletion, EM: expectation-maximization, ML: machine learning, DT: decision tree, RF: random forest, SVM: support vector machine, MLP: multilayer perceptron, kNN: k-nearest neighbor, CART: classification and regression trees.
1) Data preprocessing
This section describes the method of data preprocessing, including data preparation and cleaning, managing missing data, subgrouping factors, determining target classes, and data correlation.
(1) Data preparation and cleaning
The following two steps were taken to increase the efficiency of classifying self-harm risk.
Step 1: Factors with multiple values were removed from the dataset.
Step 2: Factors with null values in more than 10% of all records were removed from the dataset.
(2) Missing data management
In this study, we chose two techniques for handling missing data: the listwise deletion (LD) technique and the expectation- maximization (EM) technique. The LD technique is a simple method of deleting records that contain missing data, but once the records are removed from the dataset, sufficient data must remain for analysis [10]. In most cases, if the number of records found to be lost does not exceed 10%–15%, the data can be deleted [10]. The EM technique is a complex method that can replace missing data without bias and is suitable for random distributions of the missing completely at random and missing at random types. It is a calculation based on maximum likelihood estimation using a parameter estimation method, consisting of two steps: expectation (E step), which involves the log-likelihood estimation of function parameters, and maximum value (maximization; M step), which replaces missing values with the values obtained from the E step. The expected values were re-estimated and compared until very little change was obtained, and that value was used to replace the missing data [11,12].
Step 1: Replace abnormal values with null values for all factors.
Step 2: Manage the missing data using the LD and EM techniques; each technique must be conducted separately.
(3) Subgrouping factors
Some factors needed to be categorized to optimize the classification of self-harm risk and to identify patterns of self-harm risk factors.
(4) Determine the target factors
This step included defining a target group for learning to identify self-harm risks and the patterns of self-harm risk factors. After targeting the datasets, in the next step, we randomly divided the data obtained from the LD and EM techniques into partitions of 60% (to classify self-harm risk), 30% (to find patterns of self-harm risk factor), and 10% (to assess the accuracy of the self-harm risk factor patterns).
(5) Data correlation
In this step, the correlation coefficients between variables in the dataset were calculated to eliminate variables that were strongly correlated. The correlation coefficient ranges between −1.0 and +1.0. A value near −1.0 indicates a strong negative correlation, a value near +1.0 indicates a strong positive correlation, and a value of 0 indicates that there is no correlation [13]. This technique reduces the number of variables in the dataset and solves the overfitting problem, which was important because this study used many variables; the use of many variables can lead to model overfitting, thereby decreasing the effectiveness of self-harm classification and the identification of self-harm risk factor patterns. After targeting the datasets, in the next step, we randomly divided the data obtained from the LD and EM techniques into partitions of 60% (to classify self-harm risk), 30% (to find patterns of the self-harm risk factor), and 10% (to assess the accuracy of the self-harm risk factor patterns).
2) Classifying the risk of self-harm
This step classified the risk for hospital admission from self-harm using popular ML techniques for suicidality risk classification to compare the effectiveness of techniques for managing missing data. We utilized the following techniques: support vector machine (SVM) [14–20], random forest (RF) [18,19,21–24], multilayer perceptron (MLP) [18–20], DT [7,9,18], and k-nearest neighbors (kNN) [25].
These steps were performed using a 2.5-GHz Dual-Core Intel Core i5 computer with 8 GB of RAM using Python version 2.7.16. The classification used 10-fold cross-validation with the DT, RF, SVM, MLP, and ensemble (voting for DT, kNN, and SVM) techniques.
3) Data filtering
This procedure filters the data using the best techniques obtained by classifying self-harm risk from 30% of an appropriate dataset. Data filtering compares the actual and predicted answers of the best techniques and selects all the correct prediction records.
4) Identifying the patterns of self-harm risk factors
This step was performed using a 2.5-GHz Dual-Core Intel Core i5 computer with 8 GB of RAM using WEKA version 3.8.5 to find the patterns of self-harm risk factors. The identification of patterns was performed using 10-fold cross-validation with the CART technique because it is simple to understand, assigns specific values to the inputs and outputs of each problem decision, and each probability can be evaluated [26].
5) Evaluation of the self-harm risk patterns
In this step, we compared the factors in each record (10% of an appropriate dataset) with the rules derived from the CART technique and calculated the accuracy rate based on the answers in the record.
3. Ethics
Ethics approval for using the dataset in this research was obtained from the Khon Kaen University Ethics Committee for Human Research (No. HE622093) and Ethics Committee on Human Research of Khon Kaen Rajanagarindra Psychiatric Hospital.
III. Results
1. Data Preprocessing
1) Data preparation and cleaning
Step 1: Eight factors with multiple values were removed, including the patient’s name, patient’s family name, ID card number, patient identification number, visit dates, subdistrict codes, district codes, and addresses.
Step 2: Four factors with null values in more than 10% of all records were removed, including being hurt by others (19,880 visits or 10.34%), hurting others (177,125 visits or 92.14%), self-harm one or more times (110,494 visits or 57.48%) and having suicidal thoughts again (21,120 visits or 10.99%).
After data preparation and cleaning, 91 factors were left in the dataset for the next step.
2) Missing data management
The LD technique removes the records in which a null value is found. The factors in this dataset with null values are shown in Table 1. In this step, 6,601 records were deleted. The six factors for which null values most commonly caused record deletion were depression during the visit, referring hospital type, age, hospital admission, health problems, and death, with null values found in 5,293 records, 4,567 records, 3,479 records, 2,952 records, 2,551 records, and 1,425 records, respectively. Therefore, 185,633 records remained in the dataset after processing with the LD technique.

Demographics of patients and characteristics of their visits after data preprocessing
The EM technique was carried out using SPSS version 25 (IBM Corp., Armonk, NY, USA). The results for missing data management showed that the datasets managed using the LD and EM techniques had 185,633 and 192,234 visits, respectively.
3) Subgroupings of factors
In the study, two factors were categorized: (1) age was divided into five groups (i.e., under 18 years of age was represented by 1; 18–25 years of age was represented by 2; 26–45 years of age was represented by 3; 46–59 years of age was represented by 4, and older than 59 years of age was represented by 5; these age groups were classified based on the criteria of the Department of Mental Health, Ministry of Health, Thailand [27]) and (2) the region of Thailand (northern, north-eastern, central, eastern, western, and southern).
4) Determination of the target factors
There are two target classes for this study: severe self-harm risk and mild self-harm risk. Severe self-harm risk was determined based on hospital admission, death, or self-harm. Mild self-harm risk, which involved no hospitalization, death, or self-harm, is presented in Table 1.
After defining the target classes, we randomly divided the data into two datasets as follows: (1) The dataset managed using the LD technique was randomly divided into 111,380 visits, 55,690 visits, and 18,563 visits to classify self-harm risk, filter the data to find patterns in self-harm risk factors, and evaluate the patterns of self-harm risk factors, respectively. (2) The dataset managed using the EM technique was randomly divided into 115,340 visits, 57,670 visits, and 19,224 visits, which were used to classify self-harm risk, filter the data to find patterns in self-harm risk factors, and evaluate the patterns of self-harm risk factors, respectively.
5) Data correlations
In the study, factors with correlation coefficients of less than −0.9 or greater than +0.9 were selected from the dataset in Table 1. Sixty-two factors were found in the LD-processed dataset with correlation coefficients less than −0.9 or greater than +0.9 (29 factors were not deleted). In the EM-processed dataset, 57 factors had correlation coefficients less than −0.9 or greater than +0.9 (34 factors were not deleted).
After examining the correlations, we randomly divided the two datasets as follows: (1) The dataset managed using the LD technique and processed using data correlation was randomly divided into 111,380 visits, 55,690 visits, and 18,563 visits to classify self-harm risk, filter data to find patterns in self-harm risk factors, and evaluate the patterns of self-harm risk factors, respectively. (2) The dataset managed using the EM technique and processed using data correlation was randomly divided into 115,340 visits, 57,670 visits, and 19,224 visits to classify self-harm risk, filter data find patterns in self-harm risk factors, and evaluate the patterns of self-harm risk factors, respectively.
2. Classifying the Risk of Self-Harm
Based on the results presented in Tables 2 and 3, the LD technique and data correlation with the RF technique were most accurate for classifying the risk of self-harm, with area under the curve, specificity, sensitivity, and F-score of 97.52%, 92.84%, 93.12%, and 91.46%, respectively, based on 10-fold cross-validation.
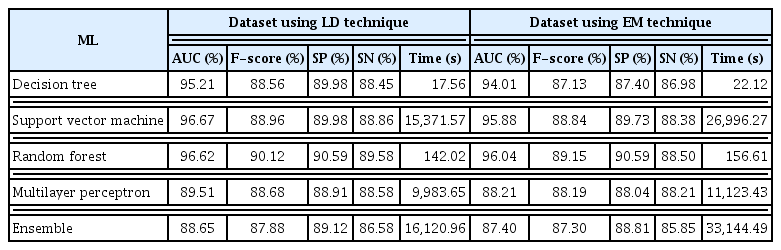
Classification of the risk of self-harm using ML techniques from the dataset using the LD and EM techniques

Classification of the risk of self-harm using ML methods from the datasets processed with the LD and EM techniques and data correlation
3. Data Filtering
This procedure filtered data using the RF technique from 55,690 visits from the dataset processed using the LD and data correlation techniques. The RF technique correctly predicted 51,235 visits and incorrectly predicted 4,455 visits, corresponding to an accuracy and inaccuracy of 92% and 8%, respectively.
4. Patterns of Self-Harm Risk Factors
There were 53 patterns of self-harm risk using the CART technique based on 10-fold cross-validation, including 16 patterns of severe self-harm risk factors, as shown in Table 4.

16 patterns of severe self-harm risk factors
Table 4 shows patterns of severe self-harm risk, presenting the meaning of each pattern for example, the ninth pattern has the following meaning: if depressive symptoms were present during the visit and the patient visited primary care, information was not received from the patient, the patient did not live in the eastern or southern region of the country, the patient was over 45 years of age, and the patient had self-harm (self-poisoning by consuming other chemicals), it was concluded that the patient was at severe risk of self-harm. As another example, the 11th pattern means that if depressive symptoms were not present during the visit and the patient had self-harm (self-poisoning by eating insecticide), it was concluded that the patient was at severe risk of self-harm. These patterns are illustrated in the decision tree in Figure 2.
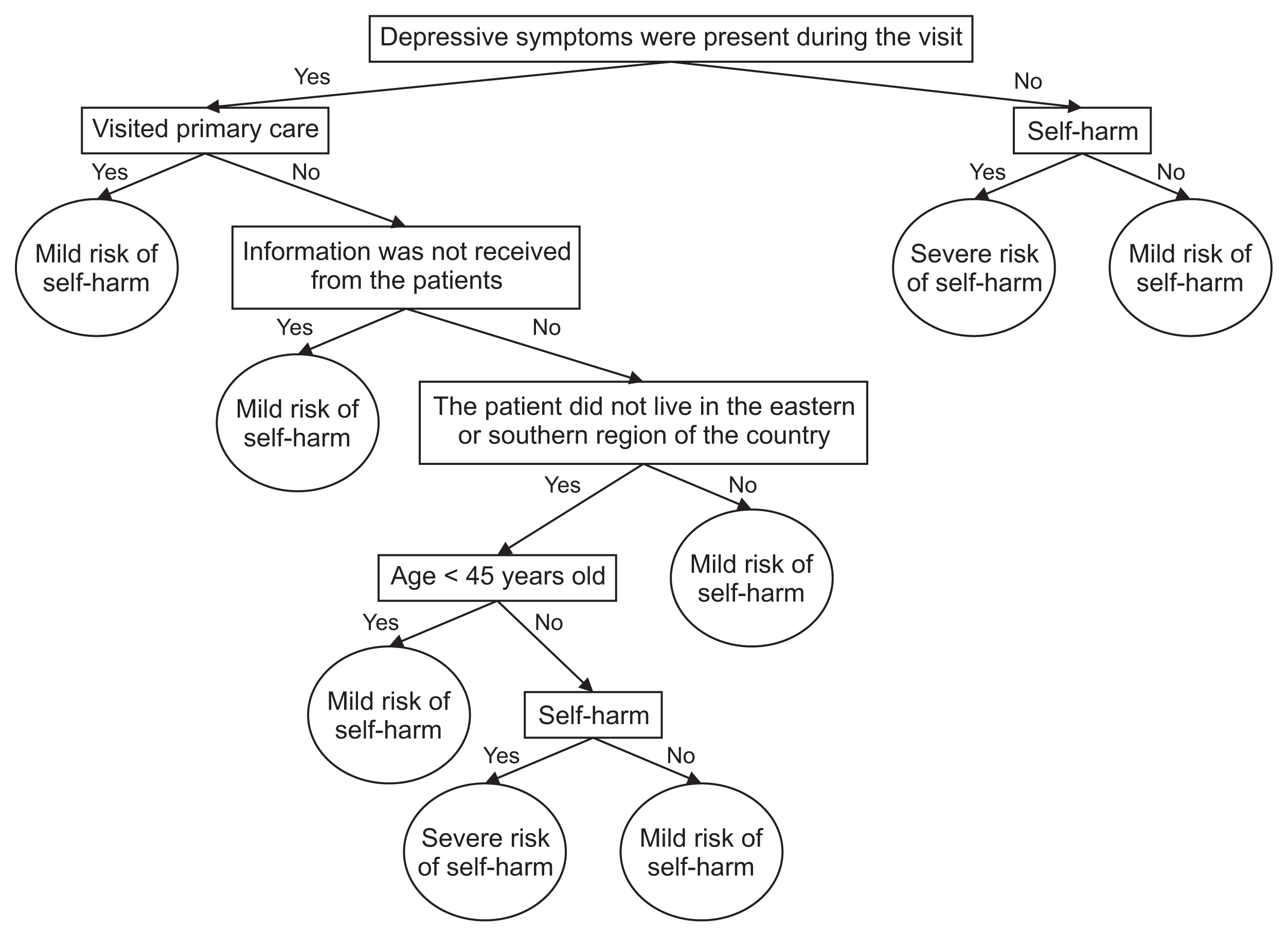
Example of a decision tree from the CART technique. CART: classification and regression trees.
5. Evaluation of the Self-Harm Risk Patterns
The results of the self-harm risk pattern evaluation using 18,563 visits from the appropriate datasets found that 53 self-harm risk patterns were able to accurately identify 17,235 visits of self-harm risk, with an accuracy and inaccuracy of 92.85% and 7.15%, respectively.
IV. Discussion
This study proved that ML techniques combined with the LD method for handling missing data provided more accurate results and required less time than the EM technique. This was because the EM technique did not replace the missing data correctly, and because the EM technique is not biased when lost data have a random loss distribution [11,12], but this dataset had a nonrandom missing distribution factor, thereby causing bias. There was likely to be a nonrandom distribution of null values for personal behavior (i.e., smoking addiction, alcohol consumption, drug addiction, gambling addiction, and others) because Thai women are less likely to provide their personal behavior information than men, especially when the information reflects their bad habits. For example, Thai women patients with drug addiction and alcohol consumption may be likely to provide null values for these behaviors if they do not want to disclose.
In this study, we used many factors, which could lead to the overfitting problem. Therefore, this problem was solved by examining correlations to reduce the number of factors. Reducing the number of factors increased the efficiency of the self-harm risk classification, consistent with previous studies [13].
To classify the risk of self-harm, we chose popular ML techniques that have been applied to suicide risk classification in previous studies. The results of the self-harm risk classification using the SVM, RF, MLP, DT, and kNN techniques were satisfactory, with an accuracy of more than 87%, proving that these techniques are suitable for use in the classification of self-harm risks [14–25]. The RF technique is most effective because it reduces overfitting in decision trees and improves accuracy and flexibility in problem classification, which corresponds to high accuracy according to prior research [17–19,21–24].
In addition, we identified 53 patterns of self-harm risk factors using the CART technique, which was highly accurate because the CART technique assigns specific values to the inputs and outputs of each decision and can work well with correlated data [26]. Most of the risk factors found in this study were consistent with previous research, including depression, agricultural workers or laborers, being under 27 years of age, region of residence, and self-harm methods [7,9]. Two important factors appeared in patterns of severe self-harm risk factors: depression and the type of hospital. People with depression feel bored, angry, and worthless, causing them to have suicidal thoughts and putting them at risk for suicide. This may lead to suicide reattempts, as found in previous studies among Japanese people [28] and Thai policemen [29]. Regarding the type of hospital, patients with minor injuries and psychiatric symptoms were generally brought to a psychiatric hospital or a specialist clinic, patients with minor injuries and no psychiatric symptoms were brought to primary care, and patients with severe injuries were admitted to a tertiary hospital to treat wounds or symptoms. Therefore, we would like to suggest that all levels of hospitals should provide specialist psychiatrists to support mental treatment after the physical injury has healed. The findings of this study extend our knowledge of risk factors and identify the type of hospital as another risk factor. These findings may encourage other researchers to consider the type of hospital when examining factors influencing self-harm.
The RP.506S dataset, which contains patient self-harm surveillance data collected from hospitals in all 76 provinces of Thailand, has the advantage of being representative of the Thai population. However, the limitations of this study were as follows: (1) we were unable to manipulate null and invalid data in the dataset, and (2) the patterns of self-harm risk factors in this study may be inaccurate if applied in other countries because the data collected were designed for use with hospitals in Thailand.
In future studies, the proposed framework can be extended to a multiclass classification problem that could include the classification of depression severity among self-harm patients (normal, mild, moderate, and severe) or a classification of types of self-harm (escape, suicide, violence, and accident). Although identifying patterns of self-harm risk may not be sufficient to diagnose self-harm patients, it may assist psychiatrists in making decisions regarding hospital admission for self-harm patients.
Acknowledgments
We would like to express our gratitude to the Director and staff of Khon Kaen Rajanagarindra Psychiatric Hospital for their support with data collection. This research is part of the dissertation titled “An algorithm for suicide prediction using machine learning techniques” by Mr. Vuttichai Vichianchai, PhD student, Khon Kaen University.
Notes
Conflict of Interest
No potential conflict of interest relevant to this article was reported.