Machine Learning Model for the Prediction of Hemorrhage in Intensive Care Units
Article information

Abstract
Objectives
Early hemorrhage detection in intensive care units (ICUs) enables timely intervention and reduces the risk of irreversible outcomes. In this study, we aimed to develop a machine learning model to predict hemorrhage by learning the patterns of continuously changing, real-world clinical data.
Methods
We used the Medical Information Mart for Intensive Care databases (MIMIC-III and MIMIC-IV). A recurrent neural network was used to predict severe hemorrhage in the ICU. We developed three machine learning models with an increasing number of input features and levels of complexity: model 1 (11 features), model 2 (18 features), and model 3 (27 features). MIMIC-III was used for model training, and MIMIC-IV was split for internal validation. Using the model with the highest performance, external verification was performed using data from a subgroup extracted from the eICU Collaborative Research Database.
Results
We included 5,670 ICU admissions, with 3,150 in the training set and 2,520 in the internal test set. A positive correlation was found between model complexity and performance. As a measure of performance, three models developed with an increasing number of features showed area under the receiver operating characteristic (AUROC) curve values of 0.61–0.94 according to the range of input data. In the subgroup extracted from the eICU database for external validation, an AUROC value of 0.74 was observed.
Conclusions
Machine learning models that rely on real clinical data can be used to predict patients at high risk of bleeding in the ICU.
I. Introduction
Hemorrhage is a serious clinical event that can result in organ failure, coma, and death. Massive bleeding requires blood transfusion, causes low perfusion-related damage to major tissues and organs, and increases morbidity and mortality [1–3]. Specifically, patients who bleed severely in intensive care units (ICUs) are often at an elevated risk of mortality and extended hospital stay [4]. In many cases, hemorrhage causes loss of blood volume, and patients with potentially fatal bleeding are a critical issue for both medical teams and blood banks [5]. Blood supplies could be delayed in life-threatening situations for various reasons, and such delays during emergencies could have irreversible adverse outcomes for patients. Therefore, it is essential to promptly recognize and treat bleeding to avoid adverse outcomes and complications. The early prediction of hemorrhage in the ICU could improve patient safety by ensuring sufficient blood management. Furthermore, since it is expensive to store unnecessarily large amounts of blood, the ability to predict hemorrhage might help in properly maintaining the blood supply chain, thereby reducing costs [6].
Electronic medical record systems have recently been established at many hospitals. These systems facilitate the management and secondary analyses of big clinical data generated in hospitals [7]. Patients with the most severe conditions are admitted to the ICU, which uses more medical resources and equipment than general wards and generates large amounts of data [8]. Machine learning, which is a branch of artificial intelligence, is instrumental in healthcare because it can be used to generate and interpret information faster than an individual medical professional. The ICU is an optimal environment for applying machine learning techniques in clinical decision-making [9,10].
Several studies have attempted to identify patient variables and biomarkers associated with bleeding, but no clear single factor or predictor has been identified that can predict hemorrhage in individual patients [11]. Hemoglobin, hematocrit, systolic blood pressure, and heart rate are known to be closely correlated with hypovolemia, and several studies have reported clinically significant parameters for the early recognition of the occurrence of bleeding [12–14]. Coagulation tests are also used to diagnose problems in the hemostatic system and can help assess the risk of excessive bleeding or thrombosis. Before surgery, coagulation tests are recommended to predict potential bleeding and blood clotting disorders [15,16]. The blood urea nitrogen test is used to measure the amount of urea nitrogen in the blood, which represents a waste product of protein metabolism [17,18]. The excessive accumulation of nitrogen-containing compounds, such as uric acid and creatinine, in the blood is associated with gastrointestinal bleeding [19]. Additionally, some studies have identified age, sex, cardiovascular disease, and kidney disease as risk factors for bleeding [11]. There are several complex predictors of bleeding, and it is necessary to integrate various factors to predict bleeding.
Several studies have been conducted on the early detection of bleeding among patients in ICUs. However, most of those studies mainly focused on patients experiencing gastrointestinal bleeding or bleeding as a complication following specific surgical procedures [20–22]. In this study, we attempted to consider all types of bleeding requiring emergency blood transfusion in the ICU setting.
We aimed to develop a machine learning model for predicting hemorrhage. Our proposed model learns the patterns of continuously changing real-world clinical data. We expected to identify groups at a high risk of hemorrhage during ICU admission in a manner that would allow pre-emptive interventions.
II. Methods
1. Data Source
In this retrospective study, we used data obtained from the Medical Information Mart for Intensive Care (MIMIC) databases. The MIMIC databases are sizeable, freely available databases comprising de-identified health-related data of patients admitted to the ICU at the Beth Israel Deacons Medical Center, which is a tertiary medical institution located in Boston, USA. The data include demographics, vital signs, laboratory results, prescriptions, and notes, among other data concerning critical patients [23]. We analyzed the most recent versions of the MIMIC databases: MIMIC-III v1.4 and MIMIC-IV v1.0. The MIMIC-III clinical database contains data obtained between 2001 and 2012. The data were collected using MetaVision (iMDSoft, Wakefield, MA, USA) and CareVue (Philips Healthcare, Cambridge, MA, USA) systems. The original Philips CareVue system (archived data from 2001 to 2008) was replaced with the new MetaVision data management system, which continues to be used today. The MIMIC-IV database contains data obtained between 2008 and 2019. The data were collected using the MetaVision system. We used CareVue data obtained from the MIMIC-III database (2001–2008) as the training dataset, except for the overlapping collection period, and we used data from the MIMIC-IV database (2008–2019) as the internal test dataset.
2. Ethics and Data Use Agreement
We completed the online human research ethics training required by PhysioNet Clinical Databases and were granted access to the data according to the procedures presented. The Ajou University Hospital Institutional Review Board approved the study protocol (No. AJIRB-MED-EXP-21-526).
3. Definition of the Outcome of Interest
We studied patients aged 18 years and above who were admitted to the ICU, as recorded in the MIMIC databases. Hemorrhage was defined as follows. First, we considered hemorrhage as occurring in patients who received transfusions of more than 1 unit of packed red blood cells (PRBCs) after admission to the ICU, based on 53 International Classification of Diseases (ICD) procedure codes (ICD-9 and ICD-10), including “control of hemorrhage” or “control of bleeding” (Supplementary Table S1). Second, we defined hemorrhage as occurring in patients who were continuously transfused with more than 1,500 mL of PRBCs within 3 hours after the start of transfusion. Among the patients satisfying either condition, we excluded those who experienced hemorrhage within 12 hours of ICU admission owing to insufficient input length. As the control group, we selected patients who did not receive blood transfusions during their stay in the ICU. Controls were matched to cases based on the length of stay at a ratio of 1:4 using propensity score-matching. Finally, we labeled the data as hemorrhage cases (n = 1,134) or controls (n = 4,536). A flowchart of the patient selection process is presented in Figure 1.
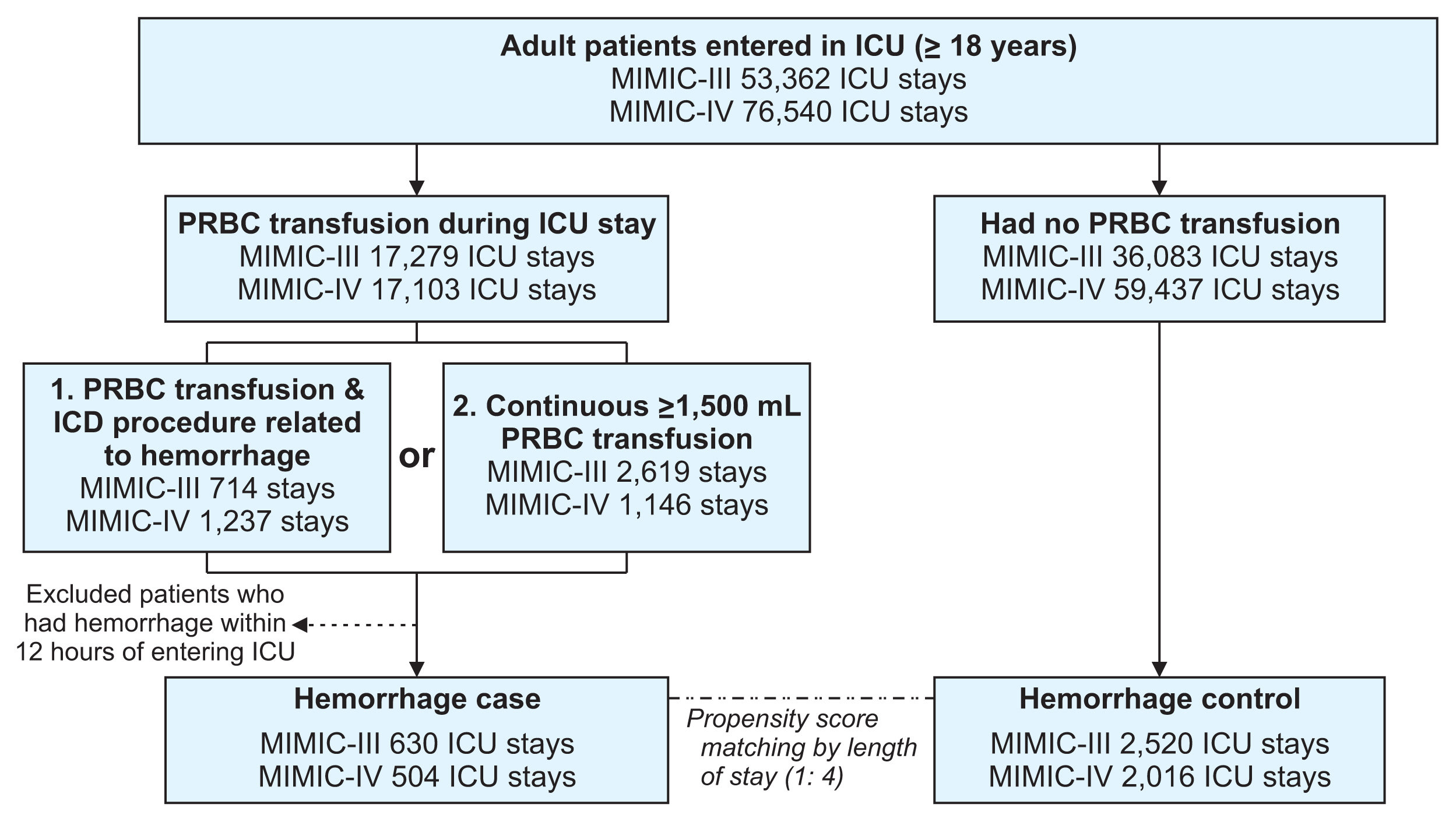
Flowchart of the patient selection process. A detailed flow chart of the patient selection process by dataset. We selected 5,670 intensive care admissions including hemorrhage cases (n = 1,134) and hemorrhage controls (n = 4,536). MIMIC: Medical Information Mart for Intensive Care, ICU: intensive care unit, PRBC: packed red blood cells.
4. Input Variables
We extracted the patient information that provided the most relevant clinical features on ICU stays from the databases. The candidate features comprised static and dynamic feature information. Patient information included patient status, vital signs, the Glasgow Coma Scale (GCS) score, complete blood count (CBC), chemistry measurements, coagulation measurements, and urine output. Patient status included four features: age, sex, weight, and the Elixhauser comorbidity index. The vital signs included seven features: systolic, mean, and diastolic blood pressure, heart rate, respiratory rate, body temperature, and oxygen saturation (SpO2). The GCS included three features: GCS eye, GCS verbal, and GCS motor. The CBC included four features: hematocrit, hemoglobin, white blood cells, and platelet count. The chemistry measurements included five features: potassium, sodium, blood urea nitrogen, creatinine, and glucose levels. The coagulation measurements included three features: partial thromboplastin time, international normalized ratio, and prothrombin time. Urine output was a single feature. We developed three machine models that included increasingly larger amounts of information (i.e., higher numbers of input features) and evaluated their performance. Model 1 was developed based only on patient status (four features) and vital signs (seven features). Model 2 used additional input information from the GCS (three features) and CBC (four features), along with the input for model 1. Model 3 used additional input information on chemistry (five features), coagulation (three features), and urine output (one feature) along with the input from model 2. The input features used for each of the three models are summarized in Table 1.

Feature overview
5. Data Preprocessing
For time-varying features, such as vital signs, we considered a 12-hour observation window before the time at which hemorrhage was predicted. The average time interval for all feature measurements within the observation window was 32 minutes for the MIMIC-III dataset and 22 minutes for the MIMIC-IV dataset. Considering the average intervals and those that can be used to divide the 12-hour observation window into the same sequence, a 30-minute interval sequence of all the features was used as the input for our proposed model. For static features, we replicated the values for each input window. Logically contradictory outliers were removed, and extreme values above the 99th percentile were replaced with values in the 99th percentile. The continuous features were then normalized to z-scores by subtracting the mean and scaling each feature into unit variance. Missing values within the observation window were replaced by linear interpolation, and the data at each point in time were sorted sequentially. The overall architecture of data preprocessing is illustrated in Figure 2.
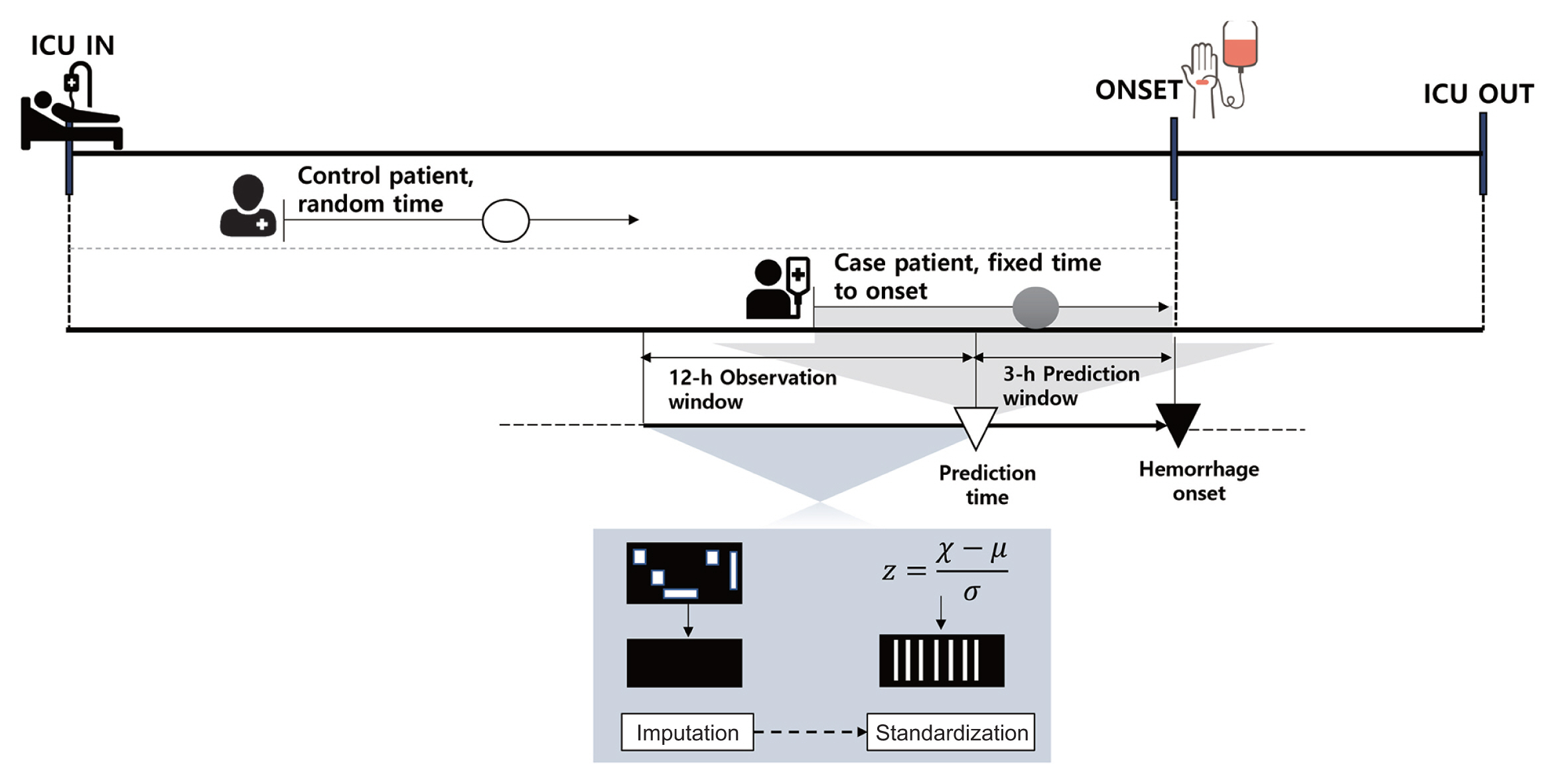
Overall architecture of data preprocessing. For patients with hemorrhage, prediction results were obtained 3 hours prior to the point of onset during the period of ICU stays, and patient data for the previous 12 hours were used as input. Control patients’ input data were extracted at random times during ICU stays. All input data were preprocessed through missing-data imputation and a standardization process. ICU: intensive care unit.
6. Model Development
In this study, to predict hemorrhage in the ICU, we used the gated recurrent unit (GRU) model, which is a modified structure of a recurrent neural network (RNN) for solving the vanishing or exploding gradient problem [24]. The GRU model is used widely for time series forecasting along with a long short-term memory network [25]. The model was designed to present predictive results for hemorrhage 3 hours before it occurs. We first designed the GRU layers, followed by sigmoid activation. We performed hyperparameter tuning for the three models. Subsequently, we found that the optimal architecture was five-layer GRUs with 20 hidden layers and Xavier initialization, followed by sigmoid activation for the three models. Figure 3 shows an architectural overview of our hemorrhage prediction models. We used a binary cross-entropy loss of over 300 training epochs using the Adam optimizer, with a learning rate of 0.001. Hyperparameter tuning was performed empirically.

Architectural overview of the hemorrhage prediction model. Dynamic features are extracted as time series, whereas static features are replicated over time. These values are integrated as a matrix of all features and labels for each patient. At each time step, the model receives current slice data as input, and features are captured in a truly sequential structure. GRU: gated recurrent unit.
7. Performance Evaluation
The hemorrhage prediction model was trained using the MIMIC-III dataset and evaluated using the MIMIC-IV dataset. The performance of the model was assessed by comparing the actual label with the label predicted using the model. True positives represent correctly classified samples belonging to a specific class. True negatives correspond to samples that do not belong to a specific class and are classified as not belonging to the class. False positives represent the samples that do not belong to a specific class but are classified as belonging to the class. False negatives are misclassified samples belonging to a specific class. We evaluated the predictive performance of our proposed model using general performance metrics: positive predictive value, negative predictive value, sensitivity, specificity, and area under the receiver operating characteristic (AUROC) curve. We also included the F1-score to compute the harmonic mean of the two scores and reflect the trade-off between precision and sensitivity. The AUROC curve has a range of between 0.5 and 1; the closer it is to 1, the better the performance. The area under the precision-recall curve (AUPRC) is the area under the curve drawn with the x-axis as the recall and the y-axis as the precision, and it is useful when there is an imbalance between labels.
8. External Validation
The eICU Collaborative Research Database (eICU) was used for external verification of model 3, which demonstrated the best performance. The eICU is an open database created through collaboration with Philips Healthcare in the United States and the MIT Laboratory for Computational Physics [26]. It comprises data collected from ICUs at more than 300 hospitals across the United States and covers patients admitted between 2014 and 2015. The eICU database does not contain information regarding the ICD procedures. Therefore, only patients who had a continuous transfusion of more than 1,500 mL of PRBC were defined as having hemorrhage, corresponding to the second condition of the outcome definition. Additionally, the data obtained from the eICU showed a lower time resolution of laboratory test results and more missing values than the data from the MIMIC database. All input features were limited to patients with values measured more than once. The measured features were used to process the 30-minute interval sequence similar to the main model. Missing values were imputed based on the patient’s last measurement. Therefore, each time step represented a recent measurement. This is the most realistic approach because doctors also observe the last measurement when evaluating a patient’s status. Forty-four patients were selected as hemorrhage cases, and 176 controls were selected through the same propensity score-matching process.
For patient selection, data preprocessing, group matching, and the imputationentry of missing values, we used Microsoft SQL server (MSSQL; v15.0, R v4.0.3) with the tidyverse (v1.3.1), comorbidity (v0.5.3), MatchIt (v4.2.0), ggplot2 (v3.3.4), and Python v3.8.5 packages, and with the pyodbc (v4.0.0), pandas (v1.1.3), scipy (v1.5.2), and numpy (v1.19.2) modules. For model development, we used Python v3.8.5 with the sklearn (v0.24.1), pytorch (v1.9.1), matplotlib (v3.3.2), pandas (v1.1.3), and numpy (v1.19.2) modules. The model was trained using an NVIDIA GeForce RTX 2080 Ti graphics processing unit (GPU).
III. Results
The complete training set from the MIMIC-III database comprised 3,150 ICU stays, corresponding to 2,996 patients, and the test set from the MIMIC-IV database included 2,520 ICU stays, corresponding to 2,440 patients. The general characteristics of the patients are expressed as numbers (%) or as mean ± standard deviation. For each numeric characteristic, the t-test was performed to compare the hemorrhage cases with the control group. The chi-square test was used to evaluate categorical characteristics. Differences were considered statistically significant if the p-value was less than 0.05 (Table 2).

Baseline characteristics in the training and test sets
Table 3 shows the distribution of the mean and standard deviation of the input features for each model. The mean value of the Elixhauser comorbidity index was higher in the hemorrhage group than in the control group. Patients in the hemorrhage group tended to have high initial severity. In the MIMIC-III dataset, the mean blood pressure in the hemorrhage group was lower, and the heart and respiratory rates were faster, but this trend was not consistent in the MIMIC-IV dataset. Hemoglobin, hematocrit, platelets, and complete blood count indicators had lower mean values in the hemorrhage group than in the control group in all datasets, and the difference was statistically significant. The measured mean differences of 18 variables in the MIMIC-III dataset and 20 variables in the MIMIC-IV dataset were statistically significant.

Statistics of input features for all three models in the training and test sets
The performance of each model with the internal test set is presented in Table 4. Model 1 used 11 input variables, including only the patient’s basic information and vital signs, and it showed an accuracy of 0.76, a sensitivity of 0.39, a specificity of 0.85, and an AUROC of 0.61. Model 2, which used a total of 18 input variables with the addition of GCS and CBC, showed improved performance compared to model 1, with an accuracy of 0.87, sensitivity of 0.75, specificity of 0.90, and an AUROC of 0.88. Using the final 27 input variables, including blood coagulation tests, electrolytes, other blood chemistry tests, and urine output, model 3 achieved an accuracy of 0.88, a sensitivity of 0.81, a specificity of 0.90, and an AUROC of 0.94.
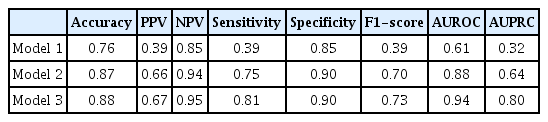
Predictive model performance in the MIMIC-IV test set
Figure 4 shows the AUROC and AUPRC curves for each model in which the number of input features was increased step by step. The AUROC and AUPRC values from model 2 were higher than those from model 1. The AUROC and AUPRC values from model 3 were higher than those from model 2. Model 3, which used data for all the input variables, showed the highest performance. These findings indicate that hemorrhage can be predicted more accurately as the number of inputs increases.
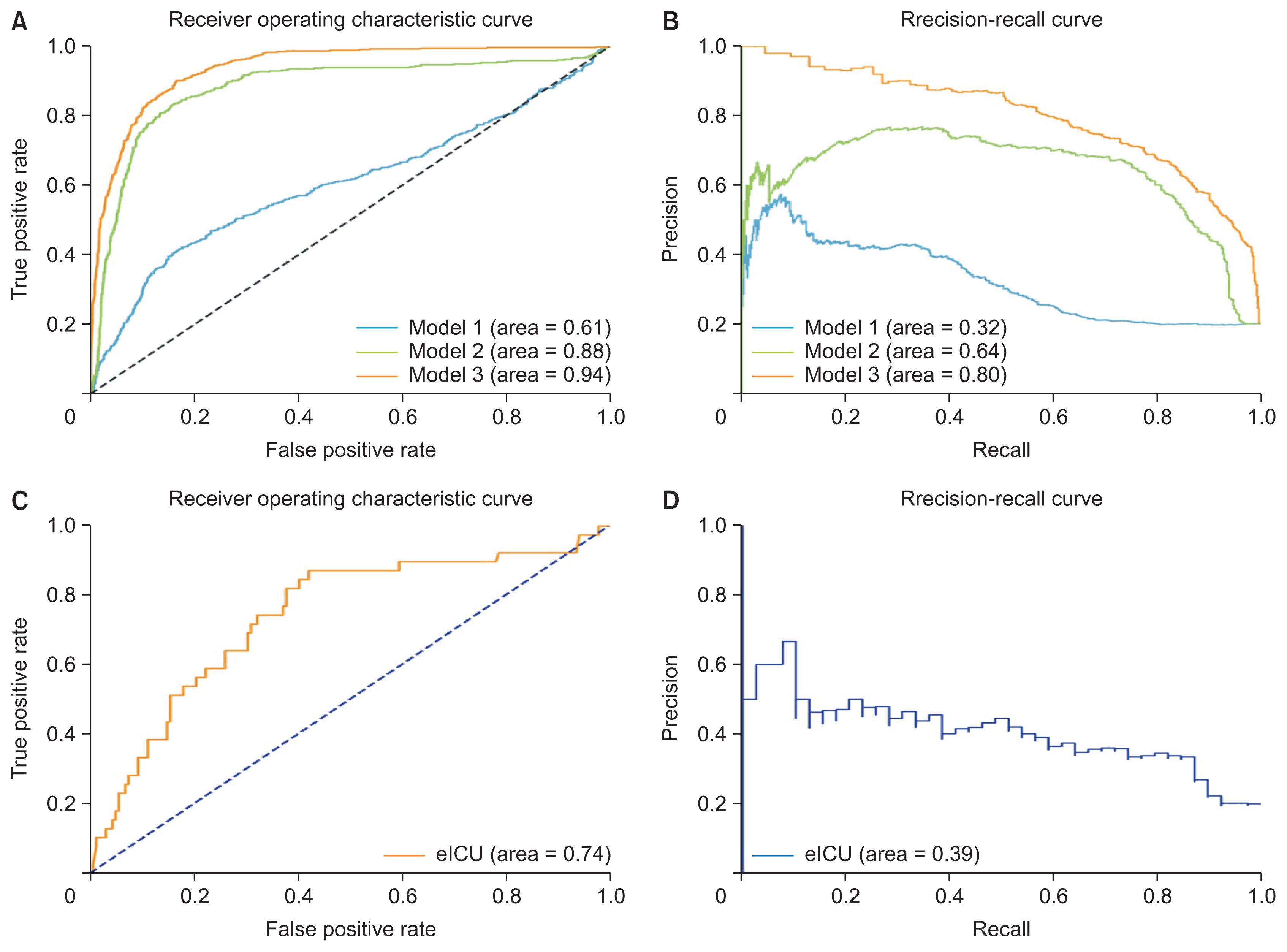
AUROC and AUPRC curves in the MIMIC-IV test and validation sets. (A) ROC curves for the different models depending on the number of input variables. (B) Precision-recall curves for the different models depending on the number of input variables. Model 3, which achieved the highest performance, was evaluated with an external dataset. (C) ROC curves for the eICU validation set. (D) Precision-recall curves for the eICU validation set. AUROC: area under the receiver operating characteristic curve, AUPRC: area under the precision-recall curve, MIMIC: Medical Information Mart for Intensive Care, ROC: receiver operating characteristic.
A subgroup of cases from the eICU database was selected by limiting the cases to those in which sufficient input variables were present, and 220 ICU admissions (44 cases of bleeding, 176 cases with no bleeding) were used for external validation. The general characteristics of the patients in the eICU database are listed in Table 5.

Baseline characteristics in the eICU dataset
We externally evaluated model 3, which showed the highest performance, using a subgroup of the eICU database. In the external validation analysis, model 3 obtained an accuracy of 0.79, a sensitivity of 0.38, a specificity of 0.88, and an AUROC of 0.74 (Table 6). This performance was somewhat lower than was observed for the test set. Figure 4 shows the AUROC and AUPRC curves for the eICU dataset.

Predictive model performance in the eICU validation set
IV. Discussion
In this study, we developed a machine learning model that uses structured electronic healthcare data to predict the risk of hemorrhage among patients admitted to the ICU. The model was designed to predict hemorrhage 3 hours before occurrence using sequential input of 12 hours of clinical observation data. We evaluated three models with an increasing number of input features. Model 3, which used the most input variables, showed the best performance, with a sensitivity of 0.81, specificity of 0.90, and AUROC of 0.94. Of note, the MIMIC-III and MIMIC-IV databases used different data collection periods, enabling the verification of retrospectively collected data using prospective data.
Model 1 used basic patient status and the most frequently measured vital sign parameters. In model 2, the CBC indicators had close correlations with bleeding and patient consciousness. In model 3, all the extracted and available variables were used as inputs. The best performance was observed for model 3, suggesting that performance could be improved by constructing models that learn the complexity of increasing amounts of data and by having models learn sequentially changing patient data while increasing the input variables. Additionally, we can estimate variables’ contributions to the prediction of bleeding by comparing the performance of the model depending on the added features.
Our model shows the potential to derive predictive output by monitoring individual patients in clinical settings. However, when a model is generally intended to be applied in actual clinical practice, there may be conflicts between increasing complexity and achieving stable generalization. Model 1 had the highest measurement frequencies, but did not show good predictive performance. It seems that the amount of information in model 1 alone was insufficient to predict bleeding. Model 2 showed better performance than model 1 because a sufficient data measurement frequency was ensured and a variable related to bleeding was added. All available additional variables were used in model 3, which showed the highest performance. In practice, it is rare for all patient data, including laboratory results, to be available on time, without missing values. Depending on the situation, model 2 or model 3 (or, potentially, an even more detailed model) could be used. There remains a need for attempts to determine the optimal balance, in a flexible and situation-specific manner, between the advancement of the model and its practical applicability in clinical practice.
Several tools have been developed to predict the risk of bleeding, but most are limited to patients with cardiovascular disease or those taking antithrombotic drugs [27–29]. An RNN-based model for predicting bleeding complications within 24 hours among patients after cardiac surgery showed an AUROC of 0.87 [20]. An ensemble machine learning model that predicted blood transfusion among patients with gastrointestinal bleeding in the ICU using the MIMIC-III and eICU databases showed an AUROC of 0.8035 [22]. In a study aiming to predict hemorrhage within 24 hours among surgical intensive care unit patients using several machine learning methods, a machine learning model based on least absolute shrinkage and selection operator (LASSO) regression showed an AUROC of 0.921, one based on random forests showed an AUROC value of 0.922, one based on a support vector machine (SVM) showed an AUROC value of 0.827, and an artificial neural network (ANN)-based machine learning model showed an AUROC of 0.894 [30]. Overall, studies on the development of machine learning models for predicting bleeding as an overall emergency clinical event, without limiting such models based on the patient’s history, are rare. In this study, we constructed a model for predicting all emergency bleeding events requiring blood transfusion for all patients admitted to the ICU, and our proposed model achieved performance levels comparable to those of other machine learning models proposed in previous studies.
Our proposed model demonstrated the possibility of the early detection of severe bleeding in clinical settings, and it can be used to ensure timely follow-up measures, such as massive transfusion, surgery, or vascular embolization. Specifically, when bleeding occurs among patients with severe conditions that require intensive care, if early intervention is not performed immediately, delays could threaten patient safety, thereby resulting in a significant deterioration of their health. Additionally, because blood banks are used to store and transport blood products among various hospitals, there exists an inevitable turnaround time between entering orders and the actual transfusions. Further, the supply of blood products may not always be stable. Therefore, detecting severe blood loss in advance could substantially improve the efficiency of blood supply management strategies.
This study has several limitations. First, this study used open relational databases specialized for ICUs, thereby making it difficult to obtain data pertinent to patients’ history before entering the ICU. Therefore, patients who experienced bleeding during the early stage of admission did not have sufficient data to use as input for the model. As a result, such patients were excluded from the model training process, reducing the sample size. Another limitation is that the resolution of the data over time was different for each input variable, and we collected information only from structured data. However, many recent studies have collected and actively used various types of unstructured medical data, such as high-resolution images, videos, and biosignals. In future studies, we must expand the model structure applied in this study to follow-up datasets from the time patients are admitted to hospitals and obtain various types of data containing additional information regarding patients to improve the performance of our proposed prediction model.
External verification was performed using data obtained from the eICU database to confirm the robustness and generalizability of the model. However, the results were somewhat poorer than the initial performance of this model. Because the eICU database comprises data obtained from various ICUs across the United States, the clinical data were more heterogeneous than those obtained from the MIMIC databases. There were missing blood test results, and the frequency of data measurements was low. Therefore, we performed external validation in limited subgroups, whereby the patients had measurements of all the input features more than once during the observation window. Despite these limitations, given an AUROC of 0.74, we suggest that our proposed model is worth further external verification in multiple institutions. Additionally, to enhance the effectiveness of prediction in clinical environments, it is imperative to present changing predictive results in various windows depending on the patient. In clinical practice, critical patients’ status is monitored in real time, and predictive models require continuous input data updates from admission and prediction results according to changes in patients’ status to ensure efficiency in real-world environments. In our future studies, we plan to construct our proposed model using a sliding window to support clinical decision-making.
In conclusion, our proposed machine learning model has potential for utilization as a tool for monitoring patients, with the main aim of identifying ICU patients at a high risk of bleeding in advance.
Supplementary Materials
Supplementary materials can be found via https://doi.org/10.4258/hir.2022.28.4.364.
Acknowledgments
This work was supported by the Korea Medical Device Development Fund grant funded by the Korea government (the Ministry of Science and ICT; Ministry of Trade, Industry and Energy; Ministry of Health & Welfare; and Ministry of Food and Drug Safety) (Project No. 1711138152, KMDF_PR_20200901_0095).
Notes
Conflict of Interest
DY is the founder and employee of BUD.on Inc. The other authors declare no conflict of interests.