I. Introduction
Evidence based medicine (EBM) is the conscientious, explicit, and judicious use of current best evidence in making decisions about the care of individual patients [1]. EBM is an important development in clinical practice and scholarly research [2].
Systematic review (SR) plays a key role in EBM [3]. SR attempts to identify, appraise and synthesize all the empirical evidences that meet pre-specified eligibility criteria to answer a given question [4]. Creation of a new SR or updating of an existing one takes considerable time and effort. First, the review topic and key questions are defined, and then relevant studies are retrieved from a number of different databases, such as MEDLINE and EMBASE. Next, experts select retrieved abstracts which are most likely to meet the inclusion criteria (abstract triage step). Finally, they closely read selected articles in the prior step and classify articles as included and excluded ones by pre-specified eligibility criteria (full text triage step) [5].
The new Health Technology Assessment (nHTA) center in National Evidence-based Healthcare Collaborating Agency (NECA) assesses new medical technologies introduced into Korean healthcare markets whether these technologies are safe and effective in real clinical settings or not. They review all the evidences systematically to evaluate those technologies. To date, 126 evidence reports have been completed and published [6].
Using current methods, we have not been able to cover new issues and keep even half of its reviews up-to-date [7]. We need to reduce avoidable processes in the production of research evidence [8]. Advanced information technologies can be developed and implemented to support SR by reducing the labor required while capturing high-quality evidence [3].
When an SR is first created, no data specific to this topic is available for information technologies. Cohen et al. [5] proposed a method that creates a model by training on data from a combination of other SR topics when topic-specific data is small. They compared to three systems, a baseline system using only topic-specific training data, a non-topic system using only the non-topic data sampled from the other topics and a hybrid system combining topic-specific training data with data from other SR topics. As the amounts of topic-specific training data become more available, their system preferentially incorporates these data into the model, reducing the influence of data from other topics. On average, the hybrid system improved mean area under the receiver operating characteristic (ROC) curves (AUC) over the baseline system by 20%, when topic-specific training data were scarce. In addition, the system performed better than the non-topic system at all but the two smallest fractions of topic specific training data. However, with very sparse topic-specific training data, the performance of the non-topic system on individual topics is often better than the baseline system, and is, at times, better than that of the hybrid system.
In this article, we address how the creation of SRs can be made more efficiently with machine learning (ML) techniques when the topic-specific data are small. We propose a method that creates classification models by training on articles included and commonly excluded. Inclusion and exclusion articles in SRs are judged by eligibility criteria. Those criteria are consisted of two parts; one is common exclusion criteria and the other is topic-specific inclusion/exclusion criteria. Articles excluded by common exclusion criteria are not included in other SRs regardless of topics. However, articles included or excluded by topic-specific criteria can be included or excluded in some SRs according to the topics. We hypothesized that by using commonly excluded articles across all SRs, we can automatically classify articles with better accuracy than previous works when a new SR is created.
II. Methods
We presented our methods in three parts. In the first, we described the data set used to evaluate our system. Then, we showed the classifier system and training method. Finally, we described our evaluation process.
1. Data Collection
In this study, the procedure data corpus was based on SR inclusion/exclusion judgments by the expert reviewers of the nHTA center. The expert reviewers classified articles at the abstract and full text level whether they are rigorous or not. This process is described in greater detail in earlier studies [5,9].
The reviewers classified articles by inclusion/exclusion criteria. Each article was encoded as shown in Table 1. Among criteria, there were 4 common exclusion criteria (code 1-4) across all SRs, such as grey literature (i.e., conference paper), non-original articles (i.e., review article, editorial, letter, and opinion pieces), non-human (animals) articles, and preclinical studies.
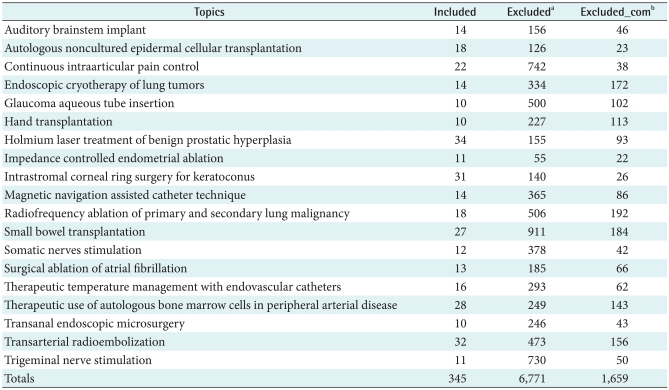
Among 126 SRs of nHTA, we selected 19 procedure SRs having more than 10 inclusion articles. Table 2 shows that the 19 review topics with the number of articles included and excluded in each study. We separated common exclusion articles (Excluded_com set) excluded by the common exclusion criteria (code 1-4) from exclusion articles (Excluded set) excluded by all the exclusion criteria (code 1-5).
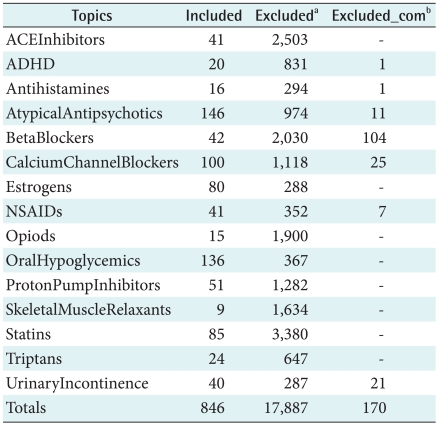
Also, we used publicly available drug SRs to confirm our method [10]. Tables 3 and 4 give information about the 15 drug topics and the inclusion/exclusion criteria [9]. We selected code 8 and 9 as common exclusion criteria across all drug SRs. Because, we thought background articles (code 8) might be non-original articles (i.e., review article, editorial, letter, and opinion pieces) and only abstract being available (code 9) might be grey literature (i.e., conference paper). We also separated common exclusion articles (code 8-9) from exclusion articles (code E-9). Looking at Table 3, the number of exclusion articles excluded by code 8 and 9 were small because most articles excluded by code E.
As can be seen in Tables 2 and 3, small number of articles was satisfied the inclusion criteria in most SRs. With small number of inclusion articles, it was not enough to the future predict. This approach may result in a model very biased towards negative (Excluded, as opposed to Included) prediction [5].
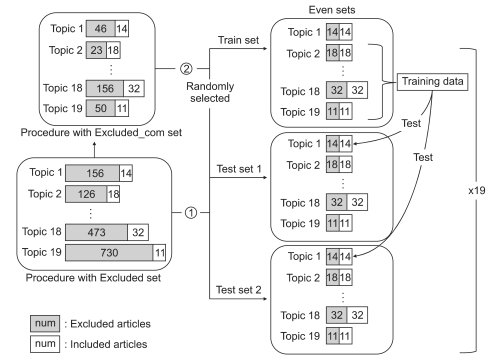
To prevent the biased prediction, we devised 'even' sets with the same number of inclusion and exclusion articles. We needed two even sets in one topic, because we divided exclusion articles into Excluded set and Excluded_com set. One was derived from Included and Excluded set (procedure/drug with Excluded even set) and the other was derived from Included and Excluded_com set (procedure/drug with Excluded_com even set). To make even sets, we randomly selected the same number of exclusion articles from Excluded set as inclusion articles if Excluded set had more articles than Included set. However, if Included set had more articles than Excluded set, we randomly selected the same number of inclusion articles from Included set as exclusion articles. For example, to make Intrastromal Corneal Ring Surgery for Keratoconus with Excluded even set, we randomly selected 31 exclusion articles from Excluded set with 140 articles, because Included set had 31 inclusion articles. This process yielded a total of 62 articles (31 exclusion and inclusion articles) as Intrastromal Corneal Ring Surgery for Keratoconus with Excluded even set. Also, to make Intrastromal Corneal Ring Surgery for Keratoconus with Excluded_com even set, we randomly selected 26 inclusion articles from Included set with 31 articles, because the Excluded_com set had 26 common exclusion articles. Intrastromal Corneal Ring Surgery for Keratoconus with Excluded_com even set had a total of 52 articles (26 exclusion and inclusion articles).
In the drug sets, we selected four topics (AtypicalAntipsychotics, BetaBlockers, CalciumChannelBlockers, UrinaryIncontinence) having more than 10 common exclusion articles, because some topics have very small number of articles in the Excluded_com sets. We also made even drug sets of four topics using the same method.
2. Classifier System
To determine the contribution of various feature types to the classification task, we used four basic feature types as below: 1) words in the titles and abstracts of a MEDLINE citation; 2) Medical Subject Headings (MeSH) indexing terms from a MEDLINE citation; 3) publication types assigned manually by the National Library of Medicine (NLM) indexers.
The titles and abstracts were parsed into tokens. MeSH indexing terms and publication types were encoded these as phrases. Individual words of the titles and abstracts were further processed by removal of stop words such as 'the', 'an', and 'other' that are not likely to add semantic value to the classification [11]. The words were also stemmed by the Porter stemming algorithm, which reduced words to their roots [12].
As titles and abstracts were narrative text, the frequency-based representation worked better for them. On the other hand, since MeSH indexing terms and publication types did not occur in an article more than once, the binary representation method might be more suitable for the feature types [3]. Therefore, we represented the titles and abstracts by word frequencies and the MeSH indexing terms and publication types as binary.
To compare the various feature combinations for the classification tasks, we combined 4 features into 6 categories given below: 1) titles + abstracts (TA); 2) titles + abstracts + MeSH (TAM); 3) titles + abstracts + publication types (TAP); 4) titles + abstracts + MeSH + publication types (TAMP); 5) abstracts + MeSH + publication types (AMP); 6) MeSH + publication types (MP).
The ML system presented here was motivated by interesting results observed in earlier studies on finding the best evidence for SRs [2,13-15]. They noticed that using the support vector machine (SVM), rather than other MLs, led to improved classification performance. In the present work, our basic ML system was the SVMlight [16] implementation of the SVM algorithm, with a linear kernel and default settings [17].
The even set of each topic had small number of inclusion/exclusion articles. However, the accuracy of prediction systems based on a small number of sampled training data was unstable [18]. To solve this problem, we made training set combining even data of other topics except own topic about 4 collections (procedure/drug with Excluded set, procedure/drug with Excluded_com set). Because no data specific to new SR topic is available for information technologies, we did not include own topic data in training set. For example, to make Auditory Brainstem Implant training set, we combined even data of other 18 topics except the topic. Tables 5 and 6 show the number of training and test data across procedure/drug SR topics.
3. Evaluation
We evaluated how well our categorization models which are trained on combination of included and commonly excluded articles perform on identifying rigorous articles for new procedure or drug SRs. In order to do that, first, we compared the classification accuracies using the various feature combinations in the procedure with Exclude set. Then, we compared the classification accuracies in the procedure/drug with Exclude set and the procedure/drug with Exclude_com set using the feature combination which shows the best classification accuracy in the procedure with Exclude set.
All collections were tested in the same processes. In the first step, we made 3 even sets in a topic; one is training set, others are test sets. We made two test sets, because randomly selected test data might affect performance results. In the second step, we combined training data of remaining topics except own topic. Finally, we built a general classification models by training on combined data of a given topic and classified 2 test sets of the topic. The accuracy was calculated for each constructed model, and all the computed results were averaged 2 test sets to give a final performance estimate. A representation of the overall process is shown in Figure 1.
We applied one-way ANOVA to compare classification accuracies of various feature combinations and t-test for results comparison of 4 collections. These statistical analyses used SPSS ver. 19 (SPSS Inc., New York, NY, USA).
III. Results
We presented the classification results of various feature combinations in the procedure with Exclude set and the accuracies in 4 collections using the best performance feature combination.
Table 7 shows the classification results of various feature combinations in the procedure with Exclude set. We found no statistical significance of the difference among them (p > 0.05). However, the MP showed the best accuracy, and was significantly better than the TAM (p < 0.05). With this result, we chose the MP as the best performance feature combination. Among topics, Therapeutic Temperature Management with Endovascular Catheters achieved the best average accuracies in 3 feature combinations (TAM, TAMP, MP) and Small Bowel Transplantation in others (TA, TAP, AMP).
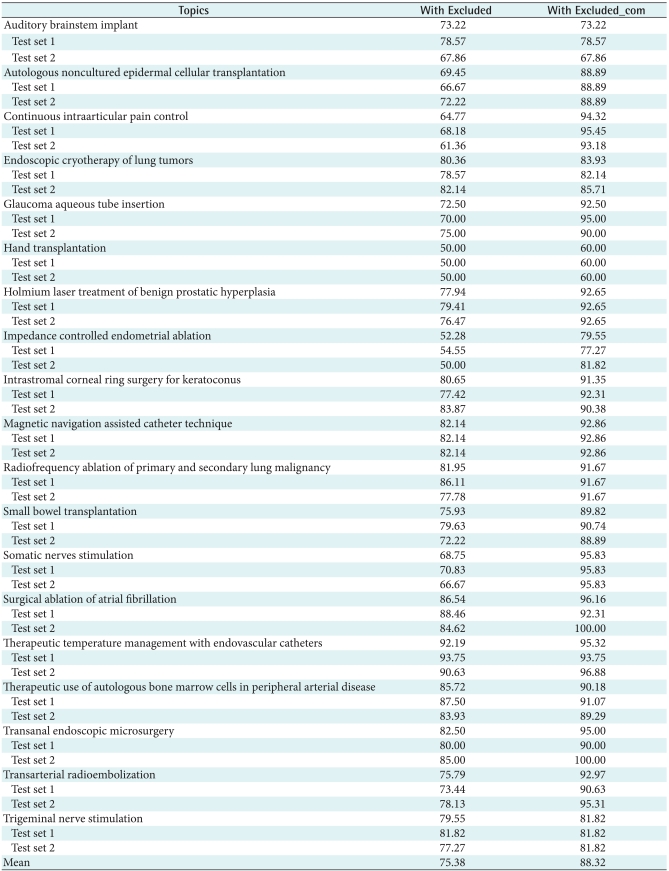
Table 8 presents the results of procedure topics using the MP which is the best performance feature combination. We found that the overall mean percentage of accuracy in the procedure with Excluded_com set (88.32%) was significantly higher than that of the procedure with Excluded set (75.38%, p < 0.05). Also, all of topics in the procedure with Excluded_com set showed high or the same accuracies compared with those in the procedure with Exclude set.
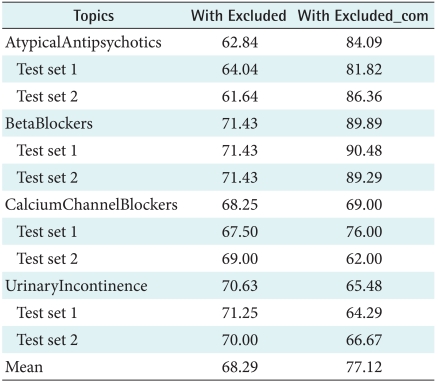
Drug results are shown in Table 9. The overall mean percentage of accuracies in the drug with Excluded_com set was better than those of the drug with Excluded set. However, there was no statistically significant difference between them (p > 0.5). All of topics in the drug with Excluded_com set showed higher accuracies than those in the drug with Excluded set, except Urinary Incontinence.
IV. Discussion
Our results showed that categorization models which are trained on combination of included and commonly excluded articles can improve articles triage performance to create SR. To improve the classification performance, we made even sets, combined even data of remaining topics except own topic, and used articles included and commonly excluded.
We compared classification accuracies of various feature combinations in the procedure with Exclude set. MP showed the best classification performance (75.38%), and the next was AMP (70.19%). TAM reported the worst classification performance (67.58%), and its overall mean percentage of accuracy was significantly lower than MP (p < 0.05). The metadata features like MeSH and publication types were benefiting the classification task, and the combination of all features (TAMP) was less successful than expected. Classification performances of feature combinations including title (TA, TAM, TAP, TAMP) were lower than other feature combinations (AMP, MP) without title. The feature combination showing the best performance (MP) was similar to that in the held-out test set to recognize methodologically rigorous studies of Kilicoglu et al. [15].
Using the best performance feature combination (MP), we tested our hypothesis that general categorization model, which is trained on the combination of included and commonly excluded articles, could classify methodologically rigorous articles with better accuracy than that which is trained on the simply combination of all articles. Overall mean accuracy of the procedure with Excluded_com set (88.32%) was significantly better than that of the procedure with Excluded set (75.38%) (p < 0.05). In all topics, accuracies of the procedure with Excluded_com set were higher than those in the procedure with Excluded set. Overall mean accuracy was 68.29% in the drug with Excluded set, and 77.12% in the drug with Excluded_com set. Except UrinaryIncontinence, accuracies of the drug with Excluded_com set were higher than those in the drug with Excluded set.
We analyzed articles encoded as 8 and 9 in 4 drug topics (AtypicalAntipsychotics, BetaBlockers, CalciumChannelBlockers, UrinaryIncontinence). Unlike our thought about code 8 and 9 in drug topics, publication types of articles encoded as 8 and 9 were various, such as Review, Comparative Study, and Clinical Trial. We classified those articles into three groups (articles excluded by our common exclusion criteria, topic-specific reasons, and other reasons). In AtypicalAntipsychotics, 45.45% of articles were excluded by our common exclusion criteria, 36.36% by topic-specific reasons, and 18.18% by other reasons. In BetaBlocker, 75.00% of articles were excluded by our common exclusion criteria, 19.23% by topic-specific reasons, and 5.77% by other reasons. In CalciumChannelBlockers, 48.00% of articles were excluded by our common exclusion criteria, 44.00% by topic-specific reasons, and 8.00% by other reasons. In UrinaryIncontinence, 23.81% of articles were excluded by our common exclusion criteria, 66.67% by topic-specific reasons, and 9.52% by other reasons. Three topics (AtypicalAntipsychotics, BetaBlockers, CalciumChannelBlockers) had more articles excluded by our common exclusion criteria than articles excluded by topicspecific and other reasons. However, UrinaryIncontinence had more articles excluded by topic-specific reasons. Classification accuracies of three topics (AtypicalAntipsychotics, BetaBlockers, CalciumChannelBlockers) having the large portion of articles excluded by our common exclusion criteria were improved in Excluded_com set. However, classification accuracy of UrinaryIncontinence having small portion of articles excluded by our common exclusion criteria was decreased in Excluded_com set.
There are several limitations to our evaluation. We randomly selected one training set and two test sets in a topic. Randomly selected one training data of a topic may not affect overall performance because we combined training data across topics except own topic. However, some randomly selected test data of a topic may poorly represent the topic and adversely affect performance. For example, Hand Transplantation, classification performance using MP was 50.00%. We thought test data of MP in Hand Transplantation might be poorly selected.
Our sample sizes are small. Although the data corpus includes 19 topics and expert judgments, overall articles are about 7,200. We used the data generated by a single SR-producing organization. It is also our limitation even if the nHTA uses the most rigorous processes to maximize quality and consistency. We tried to confirm our method using drug SRs generated by Drug Evidence Review Project (DERP) [5], but we could not evaluate our method with those articles properly. Because, in drug SRs, most articles were classified E (nonspecifically excluded) and all of articles with code 8 and 9 were not commonly excluded articles.
In conclusion, we have presented and evaluated a robust and effective method for improving the classification performance on articles for SRs. On average, performances were improved by about 15% in procedure topics and 11% in drug topics when categorization models, which are trained on combination of articles included and commonly excluded, were used. To the best of our knowledge, this is the first work in classification of scientifically rigorous studies using articles included and commonly excluded across all topics. Future work will focus on other classification features and classification algorithms to improve categorization performance.