I. Introduction
The introduction of information and communication technologies in healthcare has made it possible to collect medical and health information on patients through Electronic Health Records, digital imaging, and smart sensors [12]. This has led to an explosion of data on healthcare [23], and such data have also accumulated in cyberspace due to the development of smartphones and Internet services [3]. People search and share health-related information [4] and establish connections with people who have similar health conditions on social media [5]. Comments posted on social media can provide real-world observations of public awareness of obesity [6].
The increasing use of social media has prompted researchers to collect social media messages and analyze their meaning using social media analytics [3]. Social media analytics involves extracting and analyzing the information in messages posted on social media, such as Twitter or Facebook [2]. For instance, a study was conducted to predict suicide using social media messages presumed to be written by teenagers and to provide tailored programs for suicide prevention [7].
Text mining is one of the methods used to analyze unstructured text data from social media [289]. The accurate analysis of text data requires an understanding of the precise meaning of the terms included in documents [9] and the development of an analytic framework for data collection and analysis. An ontology is a computer-interpretable knowledge model for formalizing and representing shared concepts of the subject of interest [10]. An ontology can provide a framework to extract information from data and derive knowledge from information [1]. An ontology defines concepts related to topics, relationships of concepts, and the vocabulary to represent certain domains [11].
Health information related to obesity is often exchanged through social media. Obesity is a risk factor for several chronic diseases, such as hypertension, type II diabetes, hyperlipidemia, and coronary artery disease [12]. In Korea, the prevalence of obesity among adults aged 19 years and older was 32.5% in 2013 (37.6% in males and 27.5% in females) [13], and the medical costs of diagnosing and treating obesity are increasing rapidly [14] with a considerable associated socioeconomic burden.
The collection and analysis of social big data related to obesity could improve our understanding of the public awareness of obesity, coping strategies, and the related social phenomena. Therefore, we developed and evaluated an obesity ontology as a framework for collecting and analyzing big data on social media sites in this study.
II. Methods
This study was carried out in the three stages presented in Figure 1.
1. Development
We developed an obesity ontology according to the ‘Ontology Development 101’ described by Noy and McGuinness [11]. We used this because it provides very concrete and applicable guidance on the required tasks in each step. Its iterative design allows ontology developers revise an ontology easily [1516].
1) Determining the domain and scope of the ontology
We chose the domain and scope of our ontology based on social big data in order to answer the following questions: “How do individuals perceive the factors contributing to obesity?” “What are the sociodemographic characteristics of obese persons?” “How do individuals and healthcare providers evaluate the types and degree of obesity?” “What types of obesity exist?” “What are the results of obesity?” and “How do individuals and healthcare providers treat and prevent obesity?”
2) Considering the reuse of existing ontologies
We searched publications using the PubMed, EBSCO, and Google Scholar databases with the keyword ‘obesity ontology.’ We then reviewed the purpose of development and the extracted concepts of the retrieved ontologies to consider their utilization.
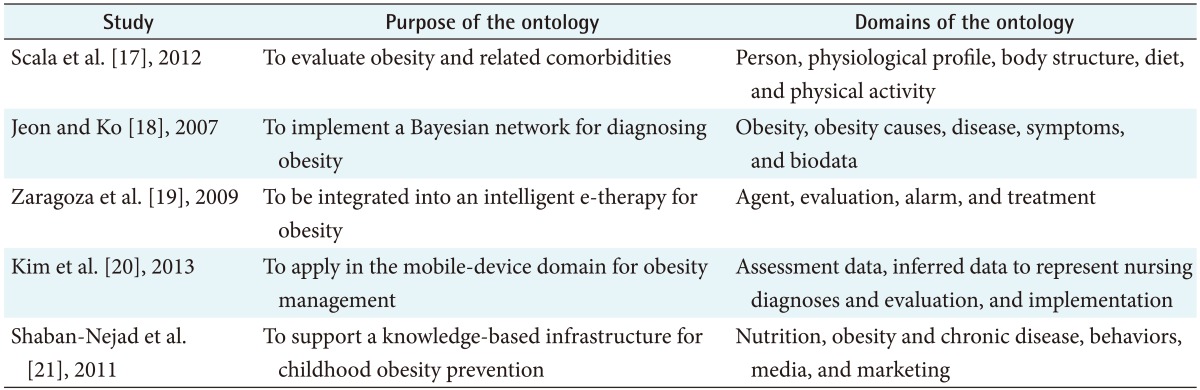
We identified five obesity-related ontologies [1718192021] whose purposes and domains are presented in Table 1. Two of the ontologies [1718] were developed for the diagnosis and evaluation of obesity, but they did not address its treatment or prevention. The obesity ontologies for intelligent e-therapy [19] and for application in the mobile-device domain [20] included not only evaluations but also interventions for obesity, but they excluded medical treatment. Finally, an ontology for supporting a knowledge-based infrastructure of childhood obesity [21] included generic and customized preventive recommendations and several risk factors of childhood obesity, but did not cover adult obesity.
Since each of the retrieved ontologies dealt with only part of obesity-related concepts, it was necessary to develop a new ontology to integrate the following concepts: factors contributing to obesity, sociodemographic characteristics of obese persons, evaluation methods, types, signs, symptoms, complications, medical treatment or interventions by healthcare providers, and self-management strategies of obesity.
3) Enumerating important ontology terms
We enumerated the important terms related to the domains and scope of our ontology. The core concepts and terms related to obesity were extracted from the clinical practice guidelines on obesity published by the National Institute for Health and Clinical Excellence (NICE) [22] and the Korean Society for the Study of Obesity (KSSO) [23]. We searched obesity-related social media postings on Internet blogs, Twitter, and Facebook from January 2011 to June 2014 by combining ‘obesity’ and obesity-related keywords representing the following domains: obesity risk factors, sociodemographic characteristics, evaluation methods, types, signs, symptoms, complications, and management strategies. We also extracted additional terms from the retrieved postings that are not included in the guidelines.
4) Defining the classes and the class hierarchy
The extracted terms were enumerated using a top-down method [11], starting from the most-general concept to more detailed concepts, to define the common concepts as classes and order them hierarchically.
5) Defining the properties of classes and their facets
The properties of classes and their facets, such as value types, allowed values, cardinality, and other features of the values, were defined to describe the internal structure of the extracted concepts.
The obesity ontology was developed by defining the relationships of the classes. The terminology was developed by linking terms to the concepts of the obesity ontology and by identifying synonyms for each concept.
2. Evaluation
1) Evaluation of the obesity ontology coverage
The coverage of the ontology developed in this study was evaluated by mapping the concepts and terms of the ontology with those extracted from the obesity-related Twitter postings. We performed a Twitter search using the combinations of keywords related to obesity (e.g., ‘diet,’ ‘exercise,’ ‘sleep,’ ‘smoking,’ and ‘drinking’) from January to March 2015 and selected the postings related to obesity. After converting them into a text file, keywords related to obesity were extracted by natural language processing using the KoNLP package in the R software. The frequencies of the extracted keywords were tallied, and any extracted keywords that were not included in the ontology were added to the revised obesity ontology.
2) Evaluation of the structure and representative ability of the ontology
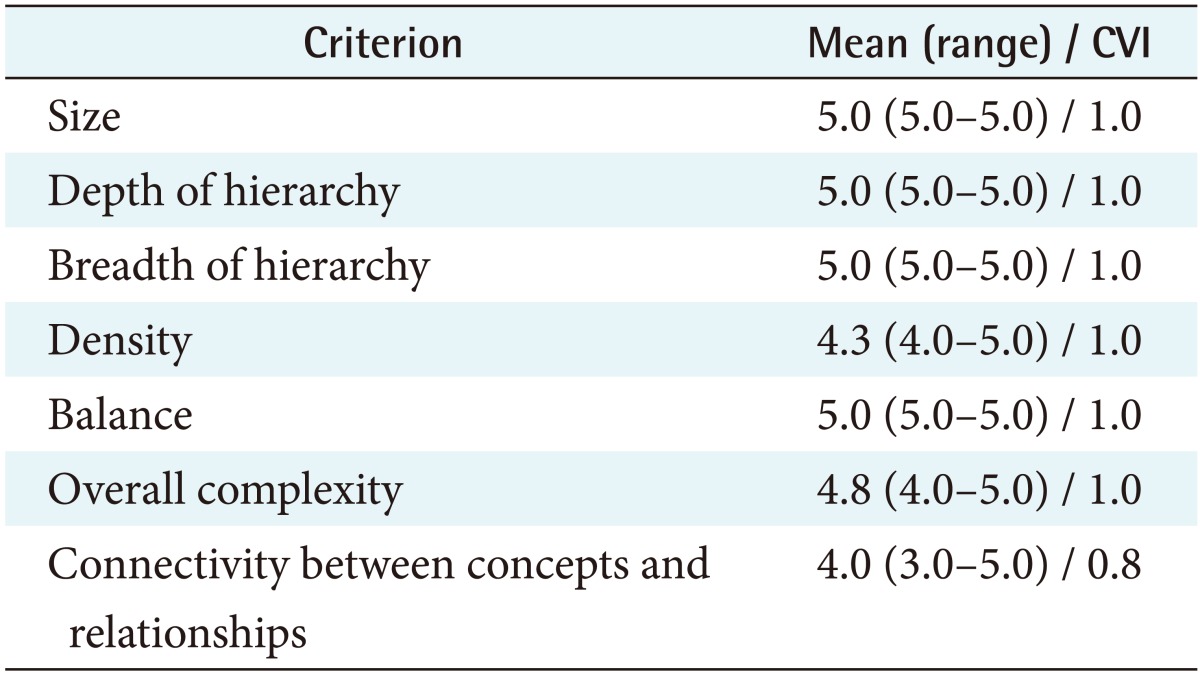
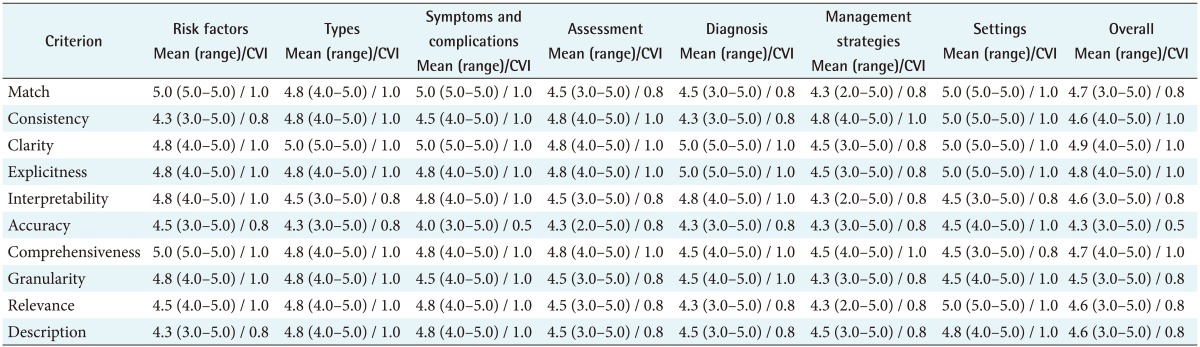
The structure and representative ability of the revised obesity ontology were evaluated by nurse experts using seven items and ten items ontology evaluation criteria on a 5-point Likert-type scale, respectively, developed by Kehagias et al. [24]. We also analyzed the content validity index (CVI) by dividing the number of experts responding to 4 or 5 points by the total number of experts for each evaluation criteria. Three experts who had a master's or higher degree in nursing informatics and one expert who had a doctoral degree in adult health nursing with experience in education and research related to obesity participated in the evaluation. The experts were asked to assess the structure of the entire ontology and the representative ability of the superclasses of the ontology.
3. Application of the Developed Ontology in the Analysis of Obesity-Related Social Big Data
We analyzed obesity-related discourses posted on social media by utilizing the ontology developed in this study. We collected social big data on obesity using the keywords of ‘obesity’ and ‘diet’ from 217 online news sites, 4 blogs, 2 social network services, and 11 online bulletin boards posted between January 2011 and December 2013. An automated software crawler was used to collect social big data for this study. We analyzed the keyword density to answer “How do individuals describe the types of obesity?” and “What kinds of obesity management strategies were described in social media postings?” We categorized the postings on obesity and diet into positive, neutral, and negative sentiments to answer “How individuals think and feel about the concepts of obesity and diet?”
III. Results
1. Development
2) Defining the classes and class hierarchy
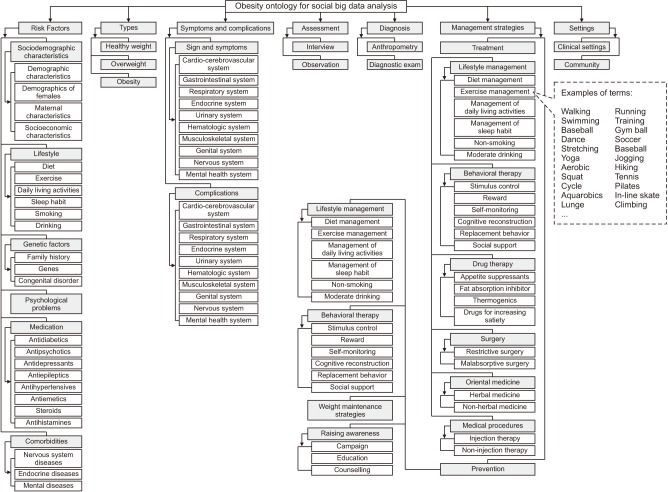
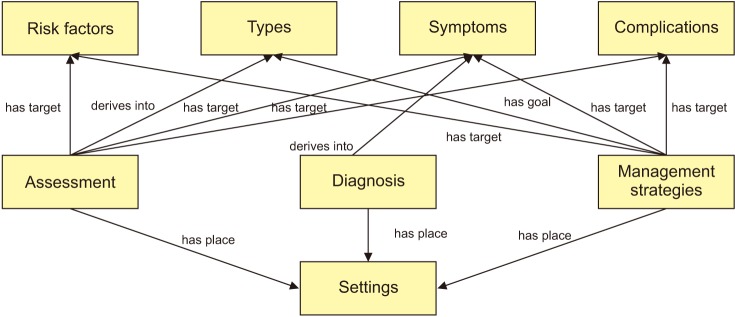
We defined the class hierarchy by creating classes for the general concepts of ‘risk factors,’ ‘sociodemographic characteristics,’ ‘assessment,’ ‘diagnosis,’ ‘types,’ ‘symptoms and complications,’ ‘treatment,’ and ‘prevention.’ We then divided these classes into specialized subclasses. We combined ‘treatment’ and ‘prevention’ concepts into the ‘management strategies’ superclass. To address the concept of the environment where assessments, diagnosis, and management strategies for obesity are conducted, the concept of ‘settings’ was added as a superclass, and ‘sociodemographic characteristics’ was moved down to a subordinate concept for ‘risk factors.’ Table 2 lists the definitions of the superclasses, depths, and number of subordinate classes. The final obesity ontology used for the collecting and analyzing obesity-related social big data comprised 7 superclasses and 148 subclasses. We present the superclasses and subclasses down to the 4th level under each superclass in Figure 2.
3) Defining the properties of the classes and their facets
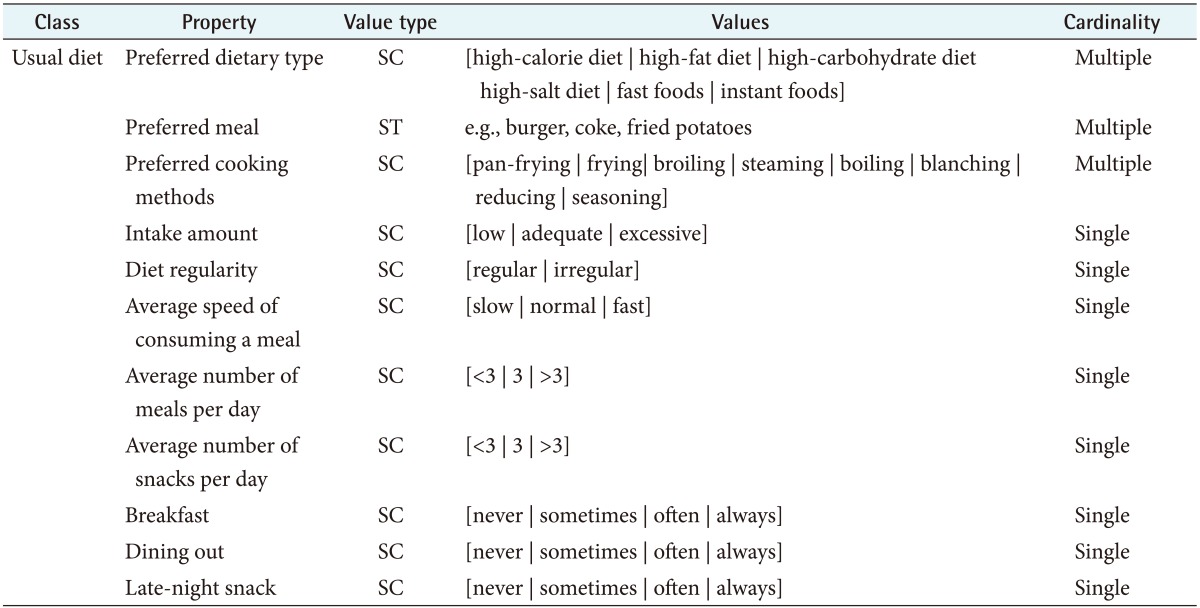
We defined the properties and their facets describing the internal structure of each concept, an example of which is presented in Table 3. On average, 4.0 properties and 2.0 relations were defined within each class.
2. Evaluation
1) Coverage evaluation of the obesity ontology
In total, 520 postings were retrieved from Twitter between January and March 2015. After excluding 79 duplicated postings, we selected 441 obesity-related postings for coverage evaluation. We manually reviewed 2,981 words extracted by natural language processing and confirmed the presence of 452 obesity-relevant terms.
Examples of terms that appeared at higher frequencies were ‘obesity’ (n = 191, 43.3%), ‘exercise’ (n = 134, 30.4%), ‘diet’ (n = 50, 11.3%), ‘lower-body obesity’ (n = 41, 9.1%), ‘fat’ (n = 37, 8.4%), and ‘treatment’ (n = 35, 7.9%). The obesity ontology developed in this study included all of these terms.
The 452 extracted terms were mapped to the classes (n = 85), properties (n = 64), and values (n = 380) with a 100% coverage rate for the concepts. However, our ontology included 397 of these 452 obesity-related terms, giving it a coverage rate of 87.8%. The 55 terms not mapped were synonyms for concepts of the classes (n = 3), properties (n = 5), and values (n = 47) of our ontology. These were mostly terms representing values of the ‘management strategies’ superclass in our ontology, such as various types of exercise (e.g., ‘dead lifts,’ ‘burpees,’ and ‘push-ups’). We revised the obesity ontology by adding these terms.
2) Evaluation of the structure and representative ability of the revised obesity ontology
Tables 4 and 5 list the evaluation scores for the structure and representability of the ontology, respectively. The experts rated all seven criteria of the ontology structure at 4.0 or higher (Table 4). The criterion with the lowest score was the relation between concepts, and an expert pointed out that the relationships between the ‘settings’ class and other classes were not clearly represented. We therefore revised the ontology by redefining the relationships between the ‘settings’ superclass with the ‘assessment,’ ‘diagnosis,’ and ‘management strategies’ superclasses.
All ten criteria for representability scored higher than 4.0 (Table 5). The criterion with the lowest score was ‘accuracy’ at 4.3, which indicates how well the ontology included the terms representing obesity-related concepts on social media. The scores for these superclasses were probably lower because these concepts included many medical terms representing drugs, diseases, or medical treatment interventions. In particular, the experts rated the ‘symptom and complications’ superclass as 4.0. One expert suggested dividing the ‘symptom and complications’ superclass into two separate superclasses because these are very different concepts. Based on this suggestion we revised the ontology with 8 superclasses and 124 subclasses (Figure 3). The terminology of the revised ontology comprised 278 terms for classes (including 162 synonyms), 147 terms for properties (including 3 synonyms), and 1,737 terms for values (including 865 synonyms).
3. Application of the Developed Ontology in the Analysis of Obesity-Related Social Big Data
We collected a total of 1,207,531 obesity-related postings that posted on social media from January 2011 to December 2013.
1) Keyword density analysis
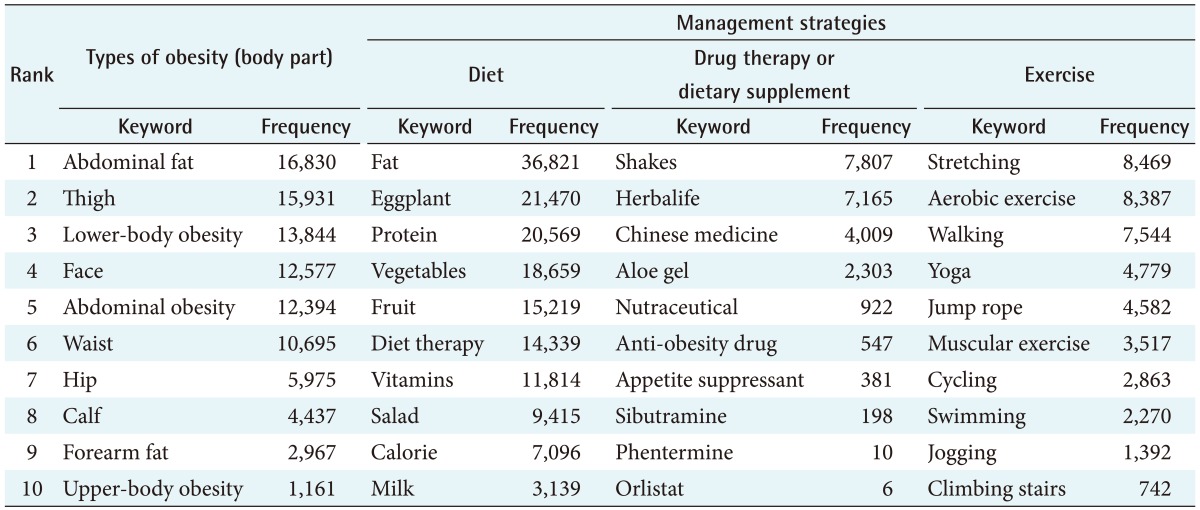
The ranks of the frequently used keywords on types of obesity and management strategies for obesity are presented in Table 6. High-frequency terms related to types of obesity were ‘abdominal fat’ (n = 16,830), ‘thigh’ (n = 15,931), and ‘lower-body obesity’ (n = 13,844). ‘Fat’ (n = 36,821) was the most frequently mentioned term related to diet. Terms related diet methods, such as ‘one-food diet,’ ‘Danish diet,’ or ‘Atkins diet’ were also mentioned frequently as diet terms. ‘Stretching’ (n = 8,469), ‘aerobic exercise’ (n = 8,387), ‘walking’ (n = 7,544), and ‘yoga’ (n = 4,779) were the high-frequency exercise terms involving activities that could be performed without any restriction of equipment or place. The terms ‘shakes’ (n = 7,807), ‘Herbalife’ (n = 7,165), and ‘Chinese medicine’ (n = 4,009) were the top-three keywords related to drug or diet supplement therapy.
2) Sentiment analysis
The results of the sentiment analysis for obesity and diet are shown in Figure 4. Neutral comments were the most common (66%), followed by positive comments (22%) and negative comments (12%) in the 1,441,939 obesity and diet related postings. The examples of the keywords from positive comments were ‘to prevent obesity’ and ‘to manage obesity,’ ‘successful diet’ and ‘healthy diet,’ and ‘helpful exercise’ and ‘effective exercise.’ The examples of the keywords from negative comments were ‘skinny fat’ and ‘super-obesity,’ ‘failed diet’ and ‘excessive diet,’ and ‘exhausted from exercise’ and ‘no time for exercise.’ It was found that the positive perception tend to increase annually during the 3-year analysis period.
IV. Discussion
In this study we developed and evaluated an obesity ontology as a framework for collecting and analyzing obesity-related social big data. The obesity ontology developed in this study comprises 8 superclasses and 124 subclasses with two to five levels deep. The terms representing the ontology classes comprises 1,121 preferred terms with 1,030 synonyms.
The superclasses of our ontology integrate all of the concepts in the existing ontologies on obesity [1718192021] such as risk factors [171821], symptoms or complications [18], diagnosis [19], assessment [1920], management strategies [192021], and settings [21]. The integrated ontology developed in this study is suitable for collecting social big data postings to answer various questions about the individual characteristics, management strategies, and environmental settings of obesity.
Our ontology incorporates terminology. The terminology of our ontology includes not only the terms extracted from the guidelines [2223] but also various terms extracted from social media postings. For example, there were ‘gynecoid obesity’ and ‘pear-shaped obesity’ as synonyms for ‘lower body obesity.’ The terminology with synonyms representing obesity-related concepts enables a rich collection of terms in social big data, and we utilized this feature in the keyword density has increased analysis on obesity types and management strategies.
Each class of our ontology has a data model with properties and possible value sets. The properties with values allowed us to conduct a sentiment analysis of obesity-related social big data. The results of the sentiment analysis showed that the rate of positive comments was higher than the rate of negative comments, and the rate of positive comments tend to increase annually during the analysis period. The postings related to effective exercise plans and diet were showed a positive awareness, while the postings related to the types of obesity and obesity as a risk factor for various chronic diseases were showed a negative sentiment on obesity and diet.
We evaluated the coverage, and structure and representative ability of our ontology. Our ontology reflected the concepts and terms that could appear in obesity-related postings from Twitter with a rather higher coverage rate above 87%. Our ontology was well represented in structure and representative ability with high scores above 4.0 out of 5 for all of the evaluation items. Some criteria, such as the connectivity between concepts and the relationships and accuracy of some superclasses were evaluated with somewhat low scores. We have modified and revised our ontology by following the opinions of evaluators.
When dealing with large data sets such as social big data, it is difficult to manage and manipulate data without a clear understanding of the concepts, structures, and characteristics of the data sets under investigation [1]. An obesity ontology as a shared conceptualization has potential uses in representing and managing obesity-related data [25]. An obesity ontology with data models and terminology of class concepts has even greater potential uses for representing and managing obesity-related unstructured social big data.
Since our ontology was developed for collecting and analyzing obesity-related social big data, it cannot provide answers to any biomedical questions on obesity, such as the underlying genetic mechanisms. It is quite possible that our ontology does not encompass all of the synonyms of the concepts because new terms will be continuously generated. Therefore, the terms representing the ontology concepts should be updated on a continuous basis.
Our findings suggest that the ontology developed in this study is suitable for collecting and analyzing social big data. A keyword density analysis related to obesity types and management strategies, and a sentiment analysis of obesity and diet using social big-data postings were possible with our ontology. Our ontology can be used in future studies to answer competency questions not studied in this study.