I. Introduction
Pressure ulcers (PUs) are defined as “localized injuries of the skin and/or underlying tissue over a bony prominence due to pressure and shear” [1]. Hospital-acquired PUs are the most concerning problems among healthcare professionals because they threaten the patients' quality of life and increase hospital costs [234]. In particular, PUs among elderly residents in long-term care facilities are prevalent in comparison with patients admitted to other types of health organizations, and their presence serves as an important indicator of care quality [56].
In Korea, long-term care facilities have rapidly increased since the implementation in 2008 of long-term care insurance, a social insurance for Korean older people, which provides physical and social support for older people and helps relieve caregivers' financial burdens [78]. The elderly in long-term care facilities do not receive intensive hospital care but need constant care services for geriatric care problems, such as PUs, falls, and cognitive impairment [910]. To provide optimal care for them in these facilities, Korean healthcare professionals have been more educated to prevent and treat these problems.
To reduce the occurrence of PUs, prevention is emphasized more than treatment is [1]. The first goal is to identify patients with specific risk factors and then to implement appropriate interventions to prevent PU occurrence [11]. Numerous studies related to risk factors for PUs have been conducted. Some individual physiological factors and organizational characteristics, such as nurse staffing levels, may place adults at risk for PU development [4]. A recent review study showed that a complex interplay of factors could increase the probability of PU development [11]. However, the quality of studies is often limited by the small sample size, analysis methods, and reporting standards [11]. These previous studies have suggested that further research is needed with adequate numbers of PUs to maximize the validity and generalizability of their findings [11].
With the widespread use of electronic health records, big data is digitally collected and stored in healthcare sections [12]. This could be a solution for this issue of generalizability [12]. In particular, the National Patient Samples (NPS)—reimbursement claim data provided by Health Insurance Review and Assessment Service (HIRA)—could be a good source for research data because the sample is representative of the total Korean patient population. Moreover, the data comprise comprehensive information on health services, including diagnoses, treatments, procedures, and administrative information, such as staffing levels [13].
However, because most big data sets, such as the HIRA NPS, are not purposely collected for research purposes and are complex. This makes it difficult to manage common and traditional tools and methods [14]. More advanced data analytics are needed to manage big data that consider a variety of variables and subjects [15].
Data mining is the process of selecting, exploring, and modeling large amounts of data to uncover events and characteristics for accurate predictions of future data [1617]. This model is non-parametric in nature and does not need the assumptions that are made in traditional statistical techniques [18]. In particular, decision tree analysis is a data mining method, and it shows a global picture of a given patient's risk. It may aid in better clinical decision-making than individual predictors obtained from a regression model [19]. Several studies have used the data mining approach to identify factors associated with disease prevention and management. Some studies have identified factors associated with postoperative recovery [20], smoking cessation failure [21], or a low-risk population for type 2 diabetes [22] using a decision tree. Raju et al. [18] and Lee et al. [23] explored factors related to PUs using a hospital database. These studies showed that the data mining approach used in a manner similar to decision tree analysis is a simple tool for predicting risk factors [22]. However, there is still a lack of studies that explore factors associated with PUs with a number of variables, including patient characteristics and administrative information.
Therefore, the purpose of this study was to explore the factors associated with PUs among elderly patients admitted to Korean long-term care facilities according to the 2014 Health Insurance Review and Assessment Service National Inpatient Sample (HIRA NIS) using decision tree analysis.
II. Methods
1. Data Source and Study Population
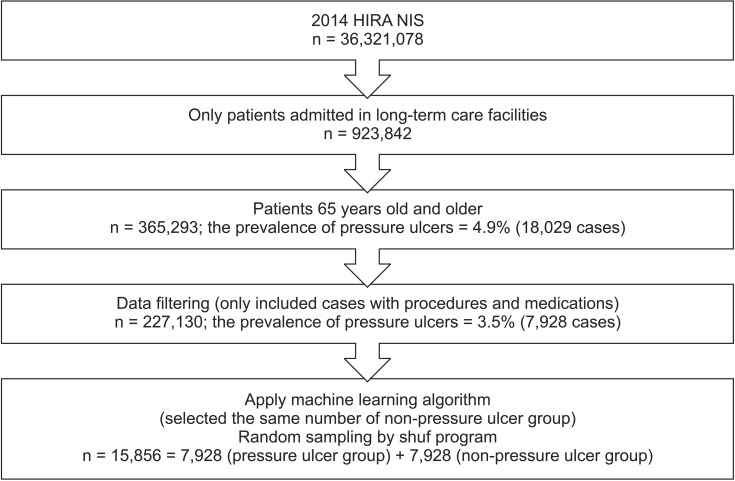
Data were extracted from the 2014 NIS provided by HIRA (HIRA-NIS-2014-0071). HIRA claims data are national data collected from healthcare providers all over the country for reimbursements for healthcare services [13]. The NIS is extracted from the HIRA claim data using a stratified randomized sampling method. Of 5,888,921 patients (estimated population), data from 765,564 patients (13%) were collected [13]. From 2014 HIRA NIS data, the inclusion criteria for this study were patients (1) admitted to Korean long-term care facilities and (2) aged 65 years or more.
2. Data Preparation
We first cleaned and preprocessed the data. An expert data manager who had skills to deal with big data analytics tools, such as Apache Hadoop and machine learning, was involved in this process. Preprocessing included initial filtering based on inclusion criteria and research interests, variable transformation and binarization, and table joining.
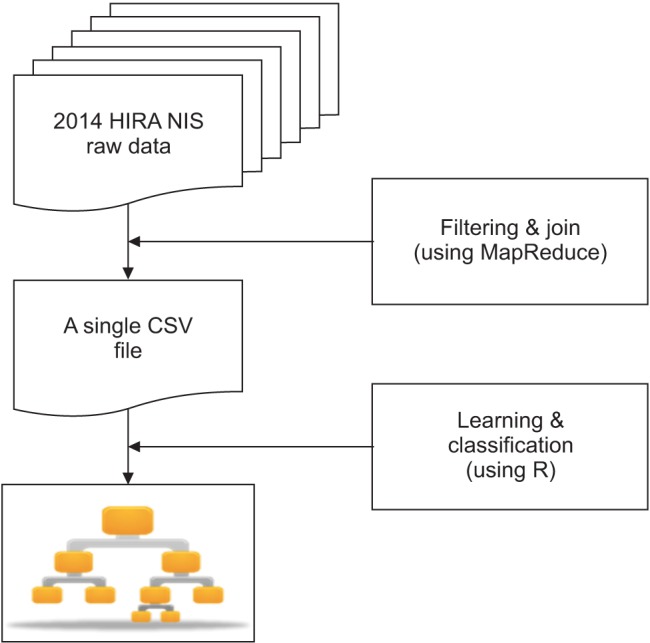
The HIRA NIS data consists of 5 tables: general specifications, health services, diagnosis information, outpatient prescription information, and health service provider information [13]. Among the 5 tables of data, the outpatient prescription table was excluded, and only cases admitted in long-term care facilities were included based on the inclusion criteria. A MapReduce-based program was implemented to join and filter those 5 tables (Apache Hadoop 2.7.1). Specifically, the billing statement identification code (key ID) was used as the key to join those 5 tables. Thus, we obtained a huge table comprising all information pertaining to the prediction task (Figure 1). MapReduce is a tool for big data analytics in healthcare, which makes it possible to process large datasets with various structures or no structure [15]. The powerful interface of this programing model enables automatic parallelization and distribution of large-scale computation to achieve high performance on large clusters of machines [24].
3. Variable Selection
Non-useful variables were initially excluded after reviewing; only medication/prescription, injection/procedure, and treatment/operation among healthcare services were included. A variable with too raw values without classification was categorized, and each category was dichotomized for a new variable. For example, drug codes in a medication variable were categorized into 34 mid-classes according to Korean drug classification [25], and each class was transformed into a binary variable. Diagnosis codes in a medical diagnosis variable were classified into 264 classes according to the subcategories of Korean Standard Classification of Diseases-7 codes (KCD-7) [26]. Each was transformed into a binary variable.
Initial machine learning was performed considering all selected variables. Based on the analysis results, a few meaningless variables were removed to improve interpretation and performance. Table 1 shows the finalized 830 variables. The final variables largely fell into three categories: demographic characteristics, disease and treatment characteristics, and healthcare provider characteristics. Demographic characteristics included age, gender, insurance type, hospital arrival pathway, length of stay, patient status at discharge, and total hospital cost. Variables related to disease and treatments were surgical status, the number of diagnoses, 264 diagnoses, 34 medications, and 517 procedures. Finally, variables related to healthcare providers were the type of providers, presence of special equipment (CT and MRI), bed grade (number of beds), and number of healthcare providers (nurse and doctor) per 50 beds.
The outcome predicted by the decision tree model was the prevalence of PUs as defined by the KCD-7 (code L89*) [26]. A binary dependent variable representing PUs was created. There were 7,928 (3.5%) PUs in 227,130 cases. The performance of machine learning was threated because the sample was skewed due to the small number of PU cases. To improve the performance, the same number of PU patients was randomly selected in 722,658 non-PU patients by the shuf program in Linux. Finally, 15,856 cases were prepared for machine learning (Figure 2).
4. Data Analysis
A decision tree was generated using R 3.3.1 to visualize associated factors and explore the patients most at risk of pressure. It could help to identify sub-populations with/without pressure through easily interpreted grouping rules [18].
The 10-fold cross-validation method was used to minimize the bias associated with the random sampling of the training. In the 10-fold cross-validation, the data set was divided into 10 parts, and then 9 parts were used for training and 1 set was used for testing. The process was then repeated until all parts were tested. The goal of this process was to determine which data mining algorithm performs best so we could use it to generate our target predictive model [16].
Three performance measures were used to evaluate the models: accuracy, sensitivity, and specificity. Accuracy is the ability to differentiate between patient and healthy cases correctly. Sensitivity is the ability to identify patient cases correctly. Specificity is the ability to identify healthy cases correctly [27]. Finally, we chose the best model with the highest accuracy based on the 10-fold cross-validation results.
Statistical analysis examined associations between PUs and predictors identified by decision tree analysis: chi-square analysis for categorical variables and independent t-test for continuous variables.
5. Ethical Consideration
This study was a secondary analysis using HIRA NIS. The NIS data obtained from HIRA were de-identified and did not contain any patient-specific information. Furthermore, this study was reviewed and exempted by the Kyungpook National University ethical committee (IRB No. 2016-0104).
III. Results
1. Characteristics of Data
Table 1 shows the data characteristics. The majority of patients were female (70.9% of the total population) and National Health Insurance subscribers (81.6%). The sample ranged in age from 65 years to 100 years (mean, 81 years). About 70% of patients were admitted via outpatient departments (OPDs). The patients had stayed for an average of 16.5 days with an average of 6.1 medical diagnoses. The average total hospital cost was US $1,200 (1,381,190.6 Korean won). Of the 264 medical diagnosis classification variables, organic including symptomatic mental disorders (KCD-7 codes, F00-F09) showed the highest frequency among patients (66.2%). In 34 drug classification variables, central nerve system drugs were the most commonly prescribed to the patients (66.0%). The most common bed grade (the number of beds) in the long-term care facilities was between 15 and 20 (15 < n ≤ 20). The facilities had an average of 0.5 physicians and 3.5 nurses per 50 beds.
2. Predictive Performance
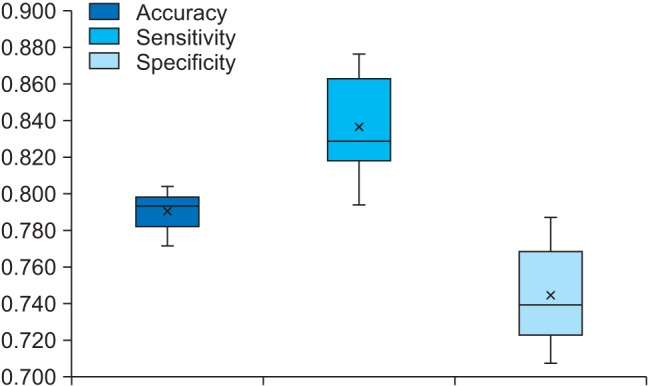
Figure 3 shows a box plot of the 10-fold cross-validation results. Accuracy ranged from 0.771 to 0.804, sensitivity ranged from 0.793 to 0.876, and specificity ranged from 0.707 to 0.787. Of the models considered, the model with the highest accuracy was selected as the best model for this study. The model showed 0.804 accuracy, 0.820 sensitivity, and 0.787 specificity. The results indicated that decision tree analysis was the best predictor with 80.4% accuracy.
3. Decision Tree
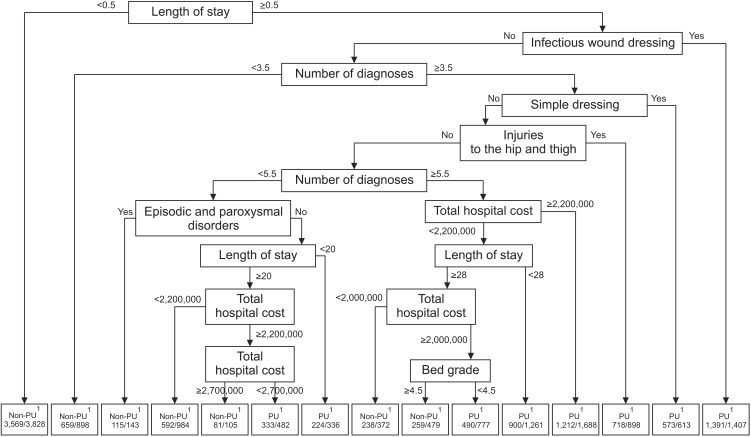
Figure 4 presents the decision tree derived from the best predictive model in the R output. Decision tree analysis identified 15 subgroups (nodes) and 8 associated factors. A length of stay shorter than 0.5 (a half) days was identified as the top associated factor with the presence of PUs. Next was the presence of an infectious wound dressing followed by a number of diagnoses less than 3.5, and then the presence of a simple dressing. Among diagnoses, “injuries to the hip and thigh” was the top predictor, ranking 5th overall, followed by a number of diagnoses less than 5.5 and episodic and paroxysmal disorders, total hospital cost, and bed grade.
The group most likely to have PUs was the 1,391 patients who stayed in the hospital for more than or equal to 0.5 days and had infectious wound dressing. The second pressure group included 1,212 patients. Patients who stayed in the hospital for a period longer than or equal to 0.5 days, who did not have infectious wound dressing, who had 3.5 or more than diagnoses, who did not have simple dressing, who did not have injuries the hip and thigh, who had 5.5 or more diagnoses were more likely to have PUs when they had total hospital cost exceeding US $2,000 (2,200,000 Korean won).
4. Variables Associated with PUs from the Statistical Analyses
Table 2 shows the association between PUs and 8 variables identified by a decision tree. There were statistically significant differences in infection wound dressing (χ2 = 1658.0, p < 0.001), simple dressing (χ2 = 985.1, p < 0.001), injuries to the hip and thigh (χ2 = 426.6, p < 0.001), and episodic and paroxysmal disorders (χ2 = 115.0, p < 0.001). Patients with these diseases and procedures had a higher proportion of PUs than patients without them. There were significant differences in length of stay (t = −33.2, p < 0.001), the number of diagnoses (t = −69.7, p < 0.001), the hospital cost (t = −41.3, p < 0.001), and the bed grade (t = 8.6, p < 0.001) between the PU and non-PU group. The PU group had longer length of stay, more medical diagnoses and hospital cost, and lower bed numbers.
IV. Discussion
This study explored the factors associated with the development of PUs using a data mining approach. The data were extracted from the HIRS NIS. A decision tree was generated with 15,856 cases and 830 variables. The decision tree displayed 15 subgroups with 8 variables showing good prediction performance. First of all, this study highlighted the usefulness of the data mining approach in managing and analyzing healthcare big data, such as the HIRA NIS data. Data mining accurately identified meaningful associations between an outcome and many variables.
The length of stay was the top variable associated with PUs. Moreover, the group with PU had a significantly longer length of stay. These results were similar to those of previous PU studies. PU could be a significant factor that prolongs the length of stay beyond expectations based on diagnosis at admission [28].
Infectious wound dressings and simple dressings were the second- and fourth-most commonly associated variables with PU. The results are quite reasonable because wound dressing is a main component of PU care. Dressings are used to keep a wound bed moist or to keep the periwound dry and prevent maceration to facilitate healing [1]. This study provides limited information regarding types of dressings because the procedure codes for the reimbursement claims did not reflect dressing types. Various types of dressings could be applied over time as an ulcer heals or deteriorates.
The number of medical diagnoses was an important variable to predict PUs. The numbers of diagnoses less than 3.5 and 5.5 were ranked 3rd and 6th splits. The number of medical diagnoses could be considered as a comorbidity. The results confirmed that comorbidity is a risk factor for PUs [29]. Of the individual medical diagnoses, “injuries to the hip and thigh” was the fifth most commonly related to PUs in. This diagnosis classification includes diseases such as ’fracture of femur‘ and ’injury of nerves at hip and thigh level‘ affecting the mobility of patients. This could be because immobility is common in patients with these diseases, and it increases the risk of developing PUs [9]. This study highlights the need for careful assessment of the elderly with higher comorbidity or these diseases to prevent PUs in long-term care facilities.
We found that total hospital cost was a factor associated with PUs, and this is supported in the literature. Multiple factors, including the prolonged stay, labor of healthcare providers, and treatment material costs can increase hospital costs [230]. Today, the increases in hospital costs caused by PUs could receive more attention due to the limited budgets for healthcare. Therefore, PU prevention is vital to reduce the costs related to PUs.
Overall, the results of this study with big data confirmed other previous study results related to PUs; our results appear to be more valid and generalizable than those of previous studies. PUs are associated with length of stay, number of diagnoses, and total hospital costs. Moreover, elderly patients with PUs are more likely to have simple, infected dressings. Eventually, longer length of stay or additional procedures, such as changing the dressing could lead to increased hospital costs for PU patients. Therefore, the importance of PU prevention to alleviate the financial burden of long-term care facilities is highlighted by this study.
Contrary to our expectation, the results did not show any drug associated with PUs even though previous research has identified specific drugs that seem to increase the incidence of PUs [411]. Further studies with pre-processing in detail could be conducted to identify other association factors.
Big data continue to impact healthcare; such information can be used to improve patient care and clinical decision-making. However, big data are very large and complex, and they are hard to manage with traditional manipulation methods. This study suggested that the use of data mining in healthcare big data can minimize the time spent manually search while minimizing insignificant studies; it can identify association [1617]. Furthermore, the decision tree analysis used in this study was used to create a model of association factors and can deal with non-linear relationships to automatically capture multilevel interactions among variables [22]. Therefore, data mining can help manage a variety of healthcare big data.
In conclusion, this study used a decision tree to find factors associated with PUs using the 2014 NIS, which is data from the HIRA. A decision tree was generated with 15,856 cases and 830 variables. The decision tree displayed 15 subgroups with 8 variables showing 0.804 accuracy, 0.820 sensitivity, and 0.787 specificity. These results support those of previous studies that showed length of stay, comorbidity, and total hospital cost were associated with developing PUs. Moreover, wound dressings were commonly used to treat PUs. Finally, this study showed that data mining methods, such as decision tree analysis, could identify outcome variables in a big data set with many variables.