I. Introduction
The changing regulatory landscape of health products has led to an increasing interest in incorporating real-world evidence (RWE) for regulatory decision-making [1]. Regulators are increasingly turning towards analytic frameworks and tools for evidence generation, using real-world data (RWD) to enhance their understanding of the benefits and risks of health products [2]. The key evidentiary needs of regulators include monitoring the effectiveness, safety, and utilization of health products in routine care [3]. Ideally, the evidence generated for regulatory purposes should be scientifically valid, timely, meaningfully contextualized, and sufficient for drawing conclusions while maintaining transparency in the evidence generation process [3].
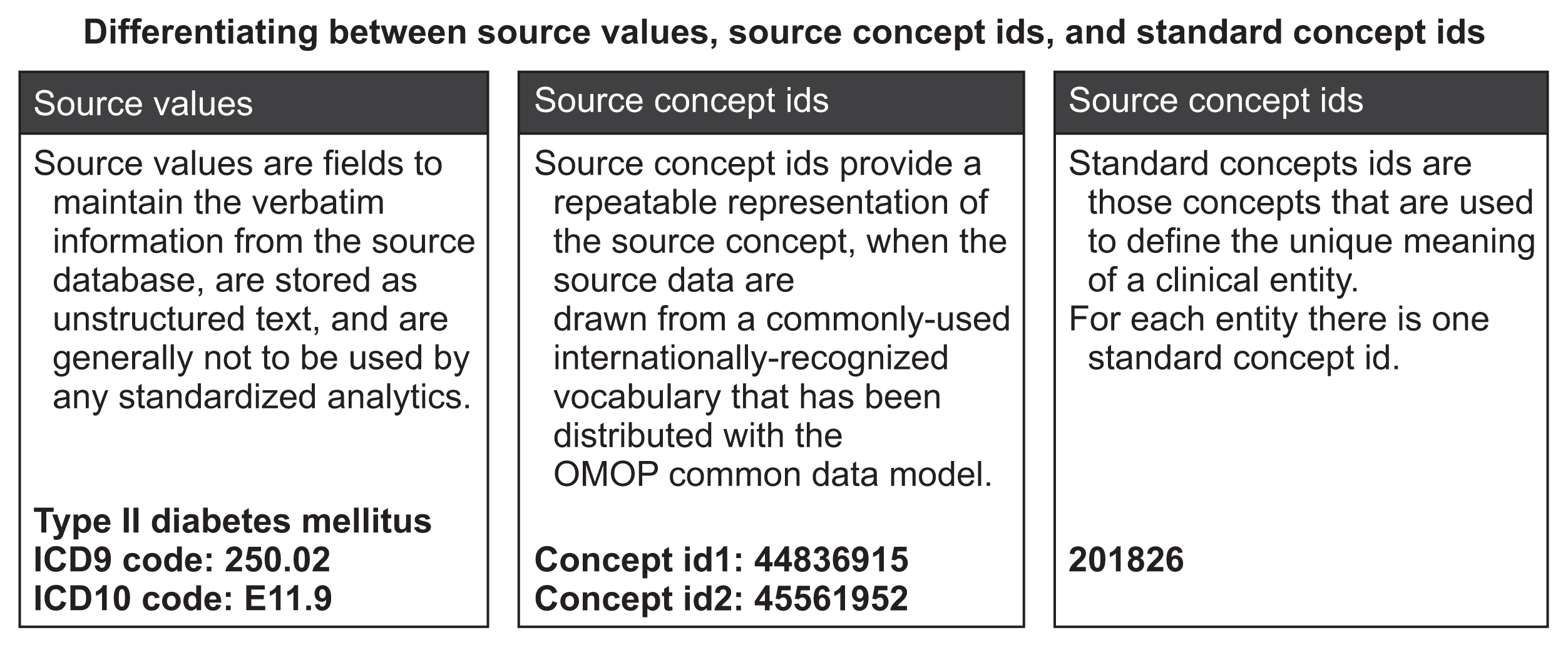
However, analysing RWD (typically from healthcare databases) and generating RWE that fulfils the aforementioned requirements can be challenging [4]. RWD is predominantly observational in nature and is rarely collected for research purposes. RWD is also often not organized in a form that is suited for analysis. Disparate data coding standards, database architectures, and vocabularies can pose further challenges in generating RWE for informing regulatory decisions, particularly when multiple databases are involved [5]. Using a common data model (CDM) may address some of these challenges by harmonizing the architectures and vocabularies of different databases, which confers analytical interoperability [6]. Converting source data into a CDM creates a copy of the original data and reshapes it to fit the common structure of the CDM. Individual data elements from source are translated to the standardized vocabularies and columns from various source tables are split or merged to fit into target table columns of the CDM [5,7]. CDM-converted databases may then facilitate multi-centre analyses and pooling of results to obtain more robust inferences for various study questions of interest [6,8ŌĆō10].
While the benefits of CDM conversion for academic purposes are relatively clear, the contribution of CDM conversion towards meeting the broad evidentiary requirements set forth for regulatory purposes remains to be elucidated [3,8]. The aim of this study was to characterize the potential usefulness of CDM conversion by conducting a sample benefit-risk assessment involving CDM-converted data. The Observational Medical Outcomes Partnership (OMOP)-CDM was selected for this study because of its large active user community and use of open-source software, which facilitates code sharing and peer review [6].
II. Methods
This study was performed in two phases. The first phase involved conversion of Electronic Medical Record (EMR) data from their source files to the OMOP-CDM, while the second phase involved an illustrative benefit-risk assessment of the converted data using available tools and code sets.
1. Phase 1: Conversion of Source Data to OMOP-CDM
1) Source data
EMR data originating from a tertiary acute care hospital in Singapore, which provides a wide range of medical and surgical speciality services, were used in this paper. The data contained information on 258,038 unique patients who visited the hospital between January 2013 and December 2016, and comprised approximately 1.1 million records of medical conditions, 5.2 million transactions of ordered medications, and 15.5 million records of laboratory tests and investigations.
2) Conversion of source data to the OMOP-CDM
A precedent for converting a portion of EMR data from Singapore was previously set [11]. Source data tables were transformed into the OMOP-CDM version 5.3.0 through three key steps. Firstly, the source data were profiled to understand its structure and content. Secondly, source data elements were mapped to a specified target location on the CDM schema, through extract, transform, and load (ETL) operations [12]. This step was facilitated by the ŌĆ£Rabbit-In-a-HatŌĆØ software, an open-source tool developed by the Observational Health Data Sciences Initiative (OHDSI) for generating flow diagrams illustrating the movement of data elements from source to target [13] (Figure 1). Lastly, vocabulary mappings were applied to translate the codes and values used in the source data to those used in the CDM.
3) Mapping vocabularies from source to target
The data vocabularies employed included the International Classification of Diseases, 9th and 10th revisions (ICD-9, ICD-10) and Systematic Nomenclature of Medicine Clinical Terms (SNOMED-CT) for diagnosis codes, RxNorm Extension for drugs, and Logical Observation Identifiers Names and Codes (LOINC) for laboratory tests and vitals measurements. In general, ETL was performed if a concept was available in the respective vocabularies and could be mapped via database joins with the OMOP concept table (Figures 2, 3). Further details on mapping of drug exposures, diagnosis codes, and laboratory tests can be found in the Supplement A.
2. Phase 2: Illustrative Analysis following CDM Conversion
1) Sample cohort assembly and drug exposure
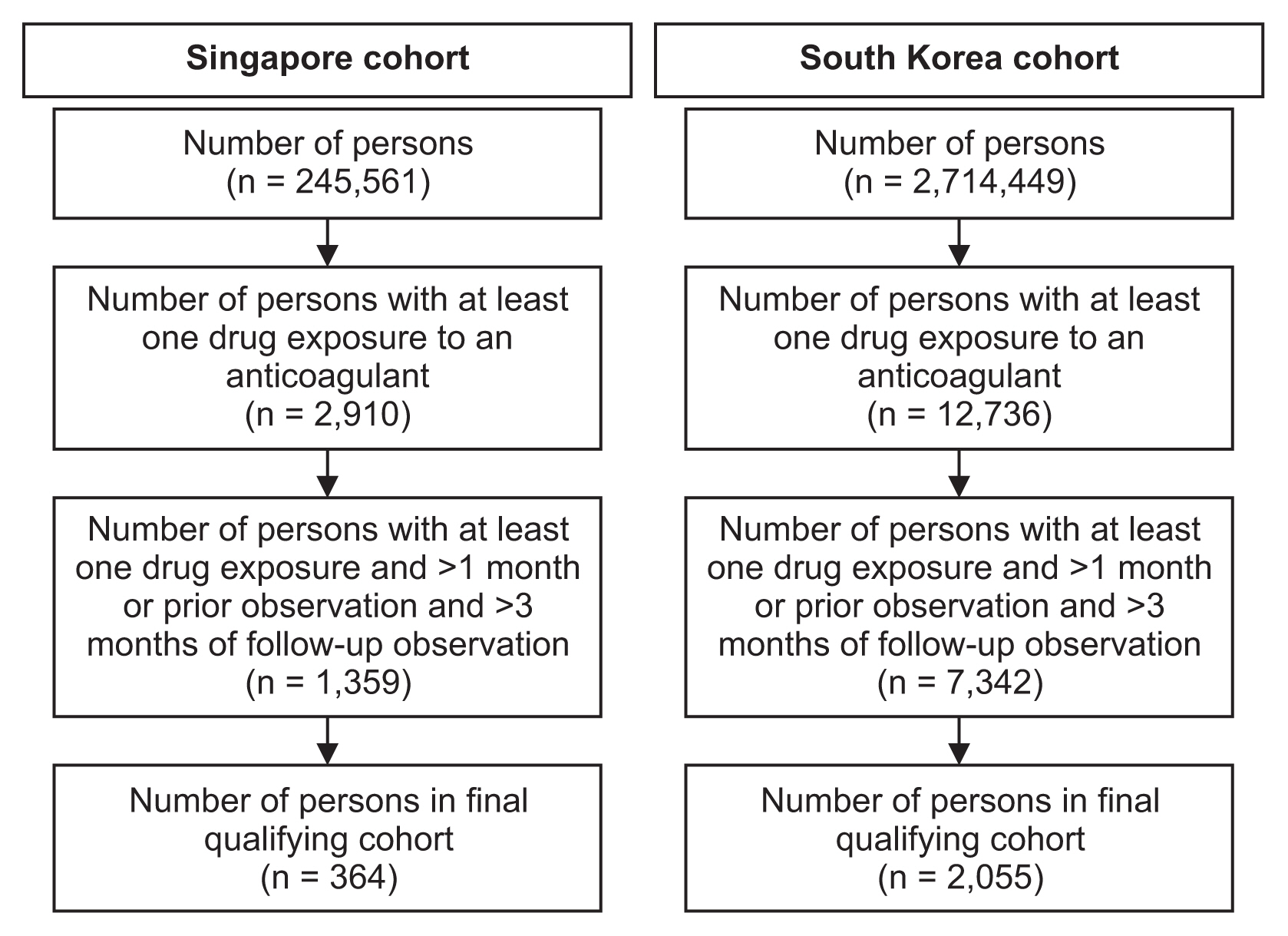
We identified patients diagnosed with atrial fibrillation (AF) without any prior bleeding and/or thromboembolic events for at least 1 month before the first oral anticoagulant (OAC; warfarin or rivaroxaban) exposure in an inpatient or outpatient setting. These patients were followed for at least 3 months after the date of first OAC exposure. Observation ended at the time of bleeding or a thromboembolic event, or at the end of the study. The pre-exposure and follow-up periods were deliberately curtailed because of the limited observation periods available in the data. Patients were included in the final cohort if they had at least one OAC dispensing record in the 3 months following index exposure in an inpatient or outpatient setting. These patients were followed up for the occurrence of bleeding or thromboembolic events at any time after the first OAC exposure. Figure 4 outlines the protocol and definitions applied in this study. Due to the different follow-up times of each patient, a landmark-based analysis at 3 months was performed to equalize the observation times of patients in both arms. More details and phenotype definitions can be found in Supplement A.
2) Visualizing comparative safety, effectiveness, and utilization for benefit-risk assessments
The outcomes of interest in the illustrative analysis were the occurrence of bleeding to represent safety and thromboembolic events to represent effectiveness (or the lack thereof). Patients in the cohort were grouped according to their OAC drug exposure, and only events that occurred during concurrent OAC exposure were extracted.
Adapting a previous OMOP-CDM study by Hripcsak et al. [14], 100%, horizontally stacked, utilization-adjusted bar charts were used to visualize drug utilization (represented by vertical bar thickness) and effectiveness and safety event proportions (represented by horizontal proportion within each bar) to facilitate multiple comparisons in benefit-risk assessments. The charts were created using R version 3.6.0 (https://cran.r-project.org). The SQL and R code used in this study is provided in Supplement B.
3) External validation of code on previously converted data and comparisons of the results of the illustrative analysis
An external validation exercise was performed to assess the validity and generalizability of the analytic code on converted OMOP-CDM data. As a mature data partner in the field of OMOP-CDM, we engaged collaborators from Ajou University, South Korea, who had converted EMR data from Ajou University Medical Center (AUMC)ŌĆöa 1,200-bed tertiary care facility providing medical and surgical speciality servicesŌĆöinto the OMOP-CDM [15,16]. The data from AUMC contained information on about 2,700,000 patients who visited the hospital between January 1994 and December 2020. The code testing exercise and comparison of results were performed to illustrate the potential of generating comparable results from different geographical cohorts of patients and to assess whether any signal of observable differences between agents compared persisted across different cohorts. This study was approved by the Institutional Review Board of Ajou University Hospital (No. AJIRB-MED-MDB-21-191), and the need for informed consent was waived due to the use of de-identified data.
III. Results
1. Phase 1: Conversion of Source Data to OMOP-CDM
Table 1 shows the quantity of data imported in comparison with the source data tables. Over 90% of records from the original table were mapped over to the CDM, except for dispensing records, which included many non-drug items such as foods, syringes, and gauzes. Other types of records not mapped to the CDM included persons with missing birth dates, as well as laboratory records where the corresponding LOINC codes were unavailable or had few records. Diagnoses involving conditional occurrences such as road accidents were excluded, as these were non-crucial for pharmacovigilance studies. Records belonging to 245,561 unique patients were converted into the OMOP-CDM.
2. Phase 2: Illustrative Analysis
A simulated risk-benefit assessment was performed to envisage the potential of OMOP-CDM-converted data in facilitating comparative assessments to inform regulatory decision-making. The results of this analysis are intended for illustrative purposes only and are not meant to be interpreted clinically.
In our sample analysis involving OACs for AF, we identified 364 patients from Singapore and 2,055 patients from South Korea who fulfilled the inclusion/exclusion criteria (Figure 5). Most patients were warfarin users: 73.9% (n = 269) in Singapore and 65.4% (n = 1,345) in South Korea. The patients in the Singaporean cohort were older than those in the South Korean cohort. Among warfarin users, the median (interquartile range) age was 70 years (15 years) in Singapore compared to 63 years (17 years) in South Korea (Table 2). The rivaroxaban users in South Korea tended to be older with median age of 69 years (14 years) than those on warfarin. The South Korean cohort also had a noticeable disparity according to sex (60.9% male, 39.1% female), while the Singaporean cohort was more balanced (51.1% male, 48.9% female). The descriptive and clinical characteristics of both cohorts are detailed in Tables 2 and 3.
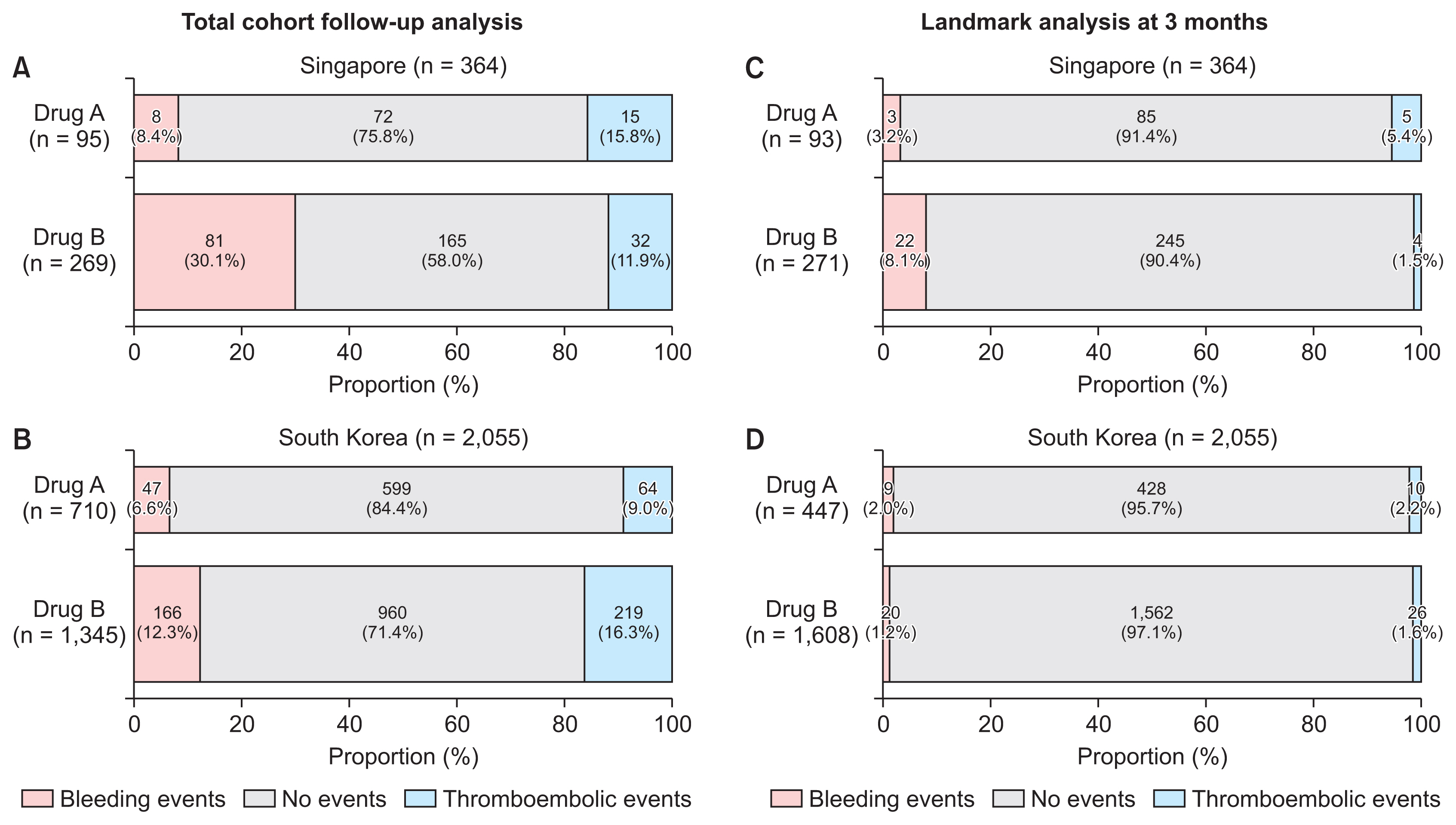
To visualize the relative proportions of individuals experiencing bleeding (safety) and thromboembolism (effectiveness or lack thereof), while accounting for differences in utilization, we propose the use of 100%, horizontally stacked, bar charts. The left (pink) and right (blue) regions of a bar are used to represent safety and effectiveness, respectively, while the central region represents the event-free proportion not experiencing any bleeding or thromboembolic events. The sections are coloured to facilitate comparisons within and between agents [17] (Figure 6).
The unadjusted analyses suggested that the overall proportion of bleeding events appeared to be higher among warfarin users than among rivaroxaban users in both cohorts (Figure 6), with the difference being more pronounced in the older Singaporean cohort. However, the higher bleeding risk with warfarin appeared to come at a trade-off for fewer thromboembolic events in the Singaporean cohort. Still, warfarin appeared to have a 3.6-fold higher bleeding risk (30.1% vs. 8.4%, p < 0.001), while rivaroxaban had a 1.4- fold higher thromboembolism risk (15.8% vs. 11.9%, p = 0.331) in Singapore. If bleeding and thromboembolism are weighted equally in terms of their impact on quality of life and survival, the relative benefits of rivaroxaban appear to outweigh the relative risks of warfarin. This insight is also available when comparing only the event-free proportions of the two agents (grey region), with rivaroxaban having 17.8% fewer overall events (75.8% vs 58.0%, p = 0.002) in absolute terms (Figure 6A, 6B). Similarly, in the South Korean cohort, rivaroxaban appears to be the preferred agent because both the proportions of bleeding and thromboembolism were higher among warfarin users than among rivaroxaban users.
However, these comparisons do not consider the different follow-up times of patients receiving the two drugs, which could contribute to the seemingly larger risks, since warfarin had a longer duration of observation in the databases studied. A landmark-based analysis was performed to equalize the observation times of patients in both arms (Figure 6). Interestingly, this eliminated any difference between the two drugs in the South Korean cohort (there were in fact smaller proportions with bleeding and thromboembolic events with warfarin than with rivaroxaban). Similarly, the benefit-risk ratio in the landmark analysis of the Singaporean cohort did not clearly favour one agent over the other (1.0% difference in event-free proportions) (Figure 6C, 6D).
IV. Discussion
Our study identified several advantages of converting healthcare databases to the OMOP-CDM related to the conduct of RWD analysis. CDM conversion inevitably involves an inspection of the source data, which can uncover data defects. Tracing to find the root cause of these errors may enable appropriate fixes to be applied. Where unresolvable errors persist, insights as to which sections of the data (or time periods of data) are best left excluded from any analysis are invaluable, as their inclusion may lead to biased results. By exposing data inaccuracies and imposing data cleaning, CDM conversion can also be considered as a process of augmenting source data veracity.
However, CDM conversion alters only the form, but not the substance of the data. This underscores the need to understand the provenance and processes that generated the data and what the data may (and may not) represent. Upon conversion, the set architecture of the CDM, the OHDSI tools, resources and opportunities (i.e., past and ongoing study protocols and, analytic code templates) create a fertile ecosystem that can speed up analyses, although some modifications and extensions to previously written code are likely required for specific use cases.
Since the previous study by Hripcsak et al. [14] focused on drug utilization patterns in chronic disease management, many code segments were reusable with simple modifications for the purposes of this study. The original code enabled easy specification of the inclusion and exclusion criteria, as well as the observation period of interest. The OMOP-CDM structure contains a derived table (termed the ŌĆ£Drug EraŌĆØ table) that meaningfully aggregates all drug exposures. This consolidated drug exposure table allows analysts to define and apply the appropriate conditions required for a study (e.g., permitted gap days between prescription fills and stockpiling of previously filled prescriptions). The ŌĆ£Drug EraŌĆØ table therefore simplifies precise exposure specifications, which are critical in pharmacoepidemiology analyses. Notably, these derived data element features are unavailable in other CDMs, such as the pCORnet, Sentinel, and i2b2 CDMs, which organize medication data at the transaction level, although there may be code segments available to instantaneously aggregate drug exposures during analysis.
The descriptive analysis of OAC usage provides insights on the background incidence of events of interest within a defined observation window. The analysis essentially covers what is described by the US Sentinel Initiative as level 1 analyses [18]. These unadjusted descriptive analyses account for more than 80% of all queries by the US Food and Drug Administration in 2020 to investigate possible drug safety signals. Level 1 analyses help regulators filter signals that warrant subsequent analyses (level 2 and beyond), which typically involve more complex methods for covariate adjustment through various approaches including propensity score matching and stratification [18,19].
Beyond these analyses, comparative assessments may be needed to holistically evaluate the overall impact of any measures undertaken to optimize public health. This would include an analysis of the benefits and risks of a drug relative to that of available alternatives, in the context of its real-world utilization for various therapeutic purposes. Regulatory actions can have far-reaching effects on public health. Benefit-risk assessments facilitate understanding of the potential consequences of various measures undertaken. Large-scale comparative effectiveness analyses have been performed using OMOP-CDM converted data [8ŌĆō10]. While these are useful, the primary focus and presentation of results in these analyses tend to focus on presenting risks on a relative scale. Regulatory agencies, however, require absolute risk estimates along with real world utilization to establish the net public health impact of policy decisions [3].
To facilitate multiple comparisons as part of benefit-risk assessments, we propose using 100% horizontally stacked bar charts (Figure 6) that amalgamate real-world utilization with effectiveness and safety information. The modularized code provided to derive these charts can be readily extended to other drug classes with composite endpoints to represent outcomes of interest (e.g., major adverse cardiovascular events). The figure facilitates comparisons of the overall prevalence of thromboembolic and bleeding events across anticoagulants at the end of follow-up. Such figures may also be useful for economic analyses, such as cost-effectiveness studies. However, unequal follow-up durations of patients on newer versus older medications are inevitable when using RWD for comparative analyses. To address this issue, we propose applying fixed time-point analyses to eliminate differential time zeros and the potential for immortal-time bias [20] (Figure 6C, 6D).
Our study has a few limitations. Firstly, the CDM conversion was only done using one hospitalŌĆÖs data; therefore, any characterization of the challenges and advantages of conversion may be limited. However, several advantages were identifiable even using only one database. Secondly, an identical analysis was not performed on pre-converted data, as the emphasis was on the possibility of using CDM for regulatory assessments rather than the technical details of conversion. As various data cleaning steps may be undertaken during conversion, not obtaining identical results (pre- and post-conversion) might be an expected outcome. Instead, we validated the analytic code by applying it on an external cohort of patients to indirectly validate the conversion process, while obtaining a separate set of results for comparison [21]. Third, the proposed 100% stacked bar graphs remain an unadjusted descriptive analysis of the rate of events in different populations exposed to comparator agents. Incorporating methods to adjust for confounders and visualize the adjusted event rates would be important areas of future research. Fourthly, the cohorts from the two countries used were demographically different, which could introduce alternative explanations for the study findings; however, studying varied populations may occasionally be desirable to evaluate the consistency of results. Nonetheless, the use of data from two countries and the evaluation of the reproducibility of the analytic code across countries may be seen as a strength of this study, as this demonstrates the potential applicability of this approach to regulators of other countries. Lastly, our study did not evaluate aspects of CDM conversion relating to the mapping coverage and speed relative to other CDMs. These may be of interest to groups looking to embark on the journey of CDM conversion.
Regulatory agencies are increasingly looking to incorporate RWE generated through the analysis of RWD for regulatory decision-making. The findings of this study demonstrate that having access to datasets in the OMOP-CDM format facilitates RWD analysis and can be useful for gleaning insights on comparative drug utilization, effectiveness, and safety for risk-benefit assessments. While the initial conversion is challenging and needs to be done judiciously, the availability of an active community of researchers and open sharing of previously written analytic code promotes transparency and scientific validity in generating RWE that is fit-for-purpose. The ability to refine previously developed analytic code with simple modifications is an important step in harnessing RWD to supplement benefit-risk assessments and enable the conduct of robust evaluations on post-market drug effectiveness and safety use cases, and ultimately make evidence-based decisions to optimise health outcomes.