Named Entity Recognition in Electronic Health Records: A Methodological Review
Article information

Abstract
Objectives
A substantial portion of the data contained in Electronic Health Records (EHR) is unstructured, often appearing as free text. This format restricts its potential utility in clinical decision-making. Named entity recognition (NER) methods address the challenge of extracting pertinent information from unstructured text. The aim of this study was to outline the current NER methods and trace their evolution from 2011 to 2022.
Methods
We conducted a methodological literature review of NER methods, with a focus on distinguishing the classification models, the types of tagging systems, and the languages employed in various corpora.
Results
Several methods have been documented for automatically extracting relevant information from EHRs using natural language processing techniques such as NER and relation extraction (RE). These methods can automatically extract concepts, events, attributes, and other data, as well as the relationships between them. Most NER studies conducted thus far have utilized corpora in English or Chinese. Additionally, the bidirectional encoder representation from transformers using the BIO tagging system architecture is the most frequently reported classification scheme. We discovered a limited number of papers on the implementation of NER or RE tasks in EHRs within a specific clinical domain.
Conclusions
EHRs play a pivotal role in gathering clinical information and could serve as the primary source for automated clinical decision support systems. However, the creation of new corpora from EHRs in specific clinical domains is essential to facilitate the swift development of NER and RE models applied to EHRs for use in clinical practice.
I. Introduction
An Electronic Health Record (EHR) is a digital repository of a patient’s medical information. Research indicates that approximately 80% of the data within EHRs are in an unstructured format, meaning they are contained in free-text documents encoded in expressive and natural human language typically used for documenting clinical proceedings [1,2]. These data can be extracted through named entity recognition (NER) or relation extraction (RE) methods, which are crucial components of natural language processing (NLP). These tasks involve identifying, extracting, associating, and classifying clinical terms such as diseases, symptoms, treatments, tests, medications, procedures, and body parts, there-by enabling the recognition of a range of clinical concepts [3]. The identification of concepts in medical texts is a critical aspect of clinical decision support systems, which are designed to assist healthcare personnel in making data-driven decisions that enhance the quality of healthcare services.
Several methods exist for extracting clinical information from EHRs, which can be categorized into two main types: rule/dictionary-based and machine learning-based. The former relies heavily on syntactic and semantic analyses, utilizing regular expressions or medical terms to match patterns within the EHR text. The latter can be further divided into traditional machine learning methods, deep learning methods, and graphical models [4]. Traditional machine learning methods encompass fully connected neural networks, support vector machines, decision trees, random forests, and other classifiers. These methods necessitate feature extraction steps, which are typically based on word embeddings [5]. Deep learning methods, for their part, consist of models based on convolutional and recurrent neural networks. Unlike traditional methods, these do not require a feature extraction step, but they do necessitate a substantial volume of data for training [6]. Finally, graphical models employ graphs to represent problems and utilize information from immediate neighbors. These models, which include hidden Markov models and conditional random fields, generally require prior feature extraction steps [7].
In the present study, we reviewed the existing NER and RE methods employed in the processing of EHRs. Additionally, we examined the trends in this field over the past decade. We made comparisons among the studies based on the classification method, which could be rule-based, traditional machine learning, graphical models, or deep learning. We also considered the type of corpus, whether private or public, the language used, and the tagging system.
This study encompasses manuscripts published from 2011 to 2022. Consequently, this review does not incorporate recent advancements published in 2023 that utilize large language models (LLMs) such as GPT-4 (Generative Pre-trained Transformer 4). However, some of these publications will be referenced in the discussion section. It remains imperative to review existing methodologies for NER in medical records for several reasons. First, medical records frequently contain domain-specific language, abbreviations, and acronyms. The majority of LLMs are trained on general-purpose corpora and may not effectively manage these specific challenges. Second, a review of existing methods allows for a comparison of performance, strengths, and limitations in future studies or applications that employ LLMs. Lastly, such a review aids in identifying gaps in data availability and underscores potential avenues for future research and dataset creation.
II. Methods
In this review, we adhered as closely as possible to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses guidelines (https://prisma-statement.org/). Our research was conducted across four databases: Science Direct, PubMed, IEEE, and the Biblioteca Virtual en Salud (VHL; https://bvsalud.org/en/). We began by identifying the keywords to construct the search string. These included terms such as “text mining,” “data mining,” “natural language processing,” “electronic health record,” and “named entity recognition.” During this initial phase (search patterns), we also incorporated synonyms or acronyms for each keyword. For example, for text mining, we included “text data mining,” “text analytics,” “text analysis,” and “text clustering.” For natural language processing, we included NLP. For electronic health records, we included “electronic medical records,” “EHR,” “EMR,” and “medical records.” For named entity recognition, we included “NER,” “named entity recognition,” and “classification,” and “NERC.” We then combined these keywords to formulate the queries, which are displayed in Appendix A.
The inclusion criteria were limited to papers published within the timeframe of January 2011 to December 2022. Furthermore, we focused solely on original articles. We utilized Rayyan (https://rayyan.ai), a free platform, to oversee the literature review process and to identify and eliminate any duplicate articles.
Subsequently, we screened titles and abstracts to exclude articles based on the subsequent criteria (utilizing the labels provided in parentheses):
• The study does not use EHRs (No EHRs).
• The study reports the application of NLP but does not mention any NER method (No NER).
• The study is unrelated to NLP (No NLP).
• The study is not reported as an original research paper, for example review articles or conference proceedings (Not Original).
• The paper is written in a language other than English (Language).
In cases where there was a discrepancy concerning any article, we ascertained whether the publication adhered to the exclusion criteria, using the information provided in the title and abstract.
Next, we screened the full texts. During full-text screening, we manually extracted the following information to describe the articles:
• Clinical domain: We identified the types of healthcare services utilized for the extraction of EHRs.
• Corpus language: We identified the language used in the development of the NER model.
• Corpus availability: We ascertained whether the study utilized private or public corpora. Additionally, we determined if the corpora were sourced from any NLP challenges.
• Tagging system: We explored the various tagging systems employed for the identification of tokens within entities that consist of multiple words.
• NLP approach: We classified the NER models into various types or approaches. These include rule-based, traditional machine learning, deep learning, and graphical models.
III. Results
Figure 1 illustrates the procedure of our methodological review. Initially, we pinpointed 588 articles, from which 152 were selected for inclusion in this study. It is important to note that a single article may be attributed to multiple reasons for exclusion. We discovered numerous articles that utilized NLP approaches, but in certain instances, they did not implement NER methods. Furthermore, we identified several articles that included medical text, but this was obtained either from social media or through web scraping.
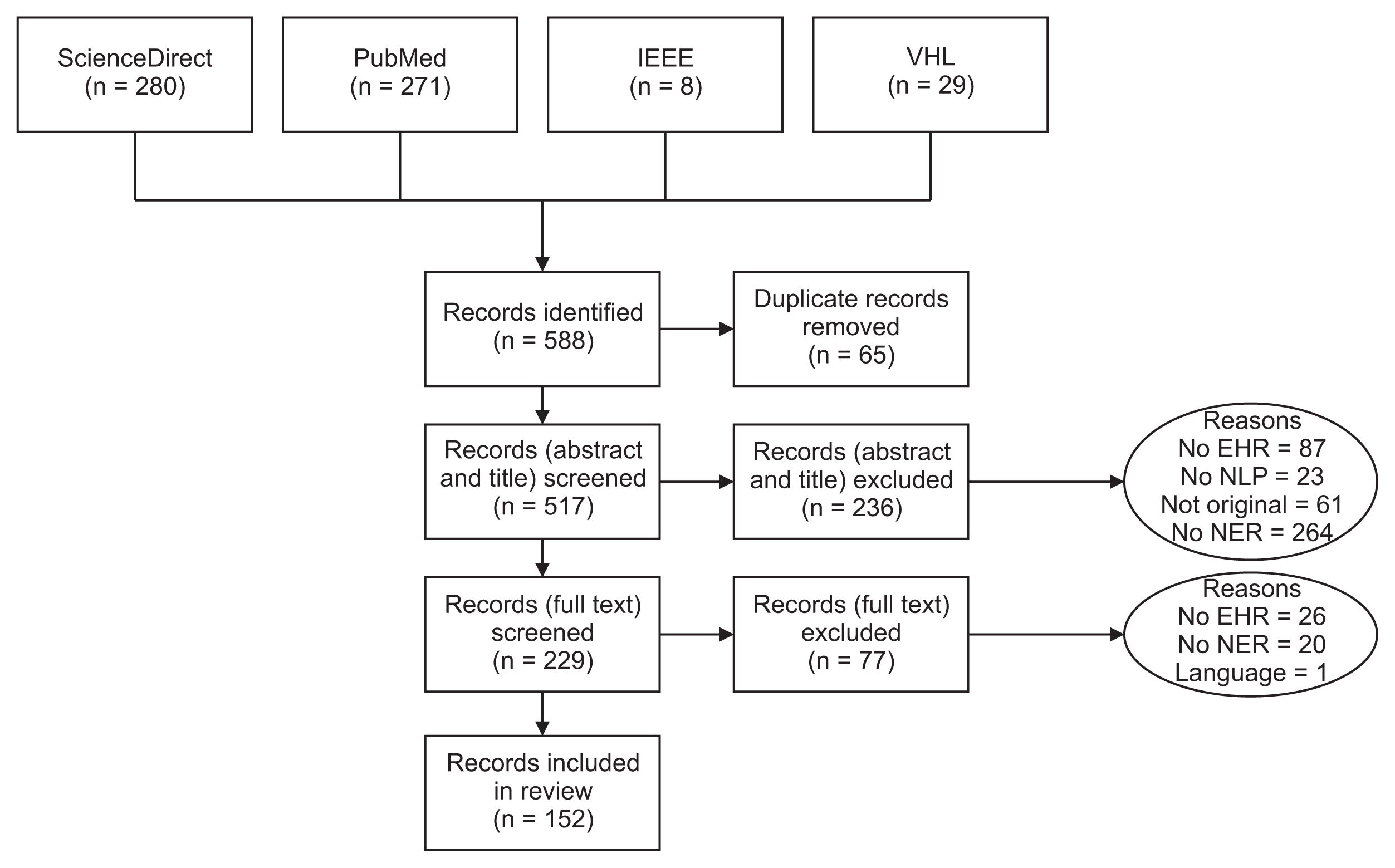
Flow diagram of the methodological review process. EHR: Electronic Health Record, NLP: natural language processing, NER: named entity recognition.
1. Classification Models
Figure 2 shows a timeline of the evolution of the NER approaches applied to EHRs, with this evolution being grounded in classification models. For instance, until 2016, rule-based methods, traditional machine learning methods, and graphical models were predominantly utilized. The support vector machine was the most frequently used traditional machine learning algorithm in the review [8–18]. In terms of graphical models, the conditional random field (CRF) was the most prevalent, primarily employed to address a label sequencing issue through NER tagging. Furthermore, the CRF model was commonly used in hybrid models or as an additional layer in the output of other models. Specifically, CRF was integrated with rule-based approaches [9,16,19–23], deep learning methods [4,24,25], and the conditional Markov model [26].

Timeline of named entity recognition models. ML: machine learning, LSTM: long short-term memory, BiLSTM: bidirectional long short-term memory, CNN: convolutional neural network, CRF: conditional random field, RNN: recurrent neural network, BiGRU: bidirectional gated recurrent unit, BERT: bidirectional encoder representations from transformers.
The first papers to report on NER models, based on deep learning and applied to EHRs, were published in 2015 [27]. By 2019, bidirectional long short-term memory (BiLSTM) had become the dominant architecture [7,28–45]. That same year, three studies were published that utilized the bidirectional encoder representations from transformers (BERT) architecture [28,43,46]. By 2021 [47–54], the BERT architecture and its variants had emerged as the primary NER model applied to EHRs, a trend that continues to this day [4,24,25,55–71]. However, this self-attention mechanism was initially introduced in 2017 [72].
Over the years, researchers have adapted various versions of the BERT model for use with EHRs. One such adaptation is BioBERT, a language representation model specifically pre-trained for the biomedical domain. This model utilizes the original BERT code and has been pre-trained using PubMed abstracts and PubMed Central full-text articles [73]. BioBERT has demonstrated good performance in biomedical NER [3,64,65]. Another example is BioClinicalBERT, which was initialized using BioBERT weights and was additionally pre-trained on the Medical Information Mart for Intensive Care (MIMIC-III) datasets [74]. MIMIC-III represents the largest freely available resource of hospital data. In addition to BioBERT and BioClinicalBERT, BlueBERT [75] is another BERT variant used for EHRs. This model was pre-trained using PubMed abstracts and clinical notes, with the aim of improving the capture of language features in the biomedical and clinical domains. This could potentially lead to enhanced performance [62]. Beyond BiLSTM and BERT, several other notable deep learning models have been explored, including convolutional neural networks (CNNs) [31,44,76–83], and the hybrid CNN-BiLSTM-CRF model [84–86]. These alternative approaches have been applied in various contexts and have been demonstrated to be particularly effective for Chinese corpora [87]. As of 2022, BERT-based models are leading the field in NER applications within electronic health records. Notably, BlueBERT has emerged as a prominent solution, while BioClinicalBERT and BioBERT have also gained popularity.
2. Tagging Systems
Figure 3 details the types of tags used in the NER studies included in this review. Such tagging systems help to represent the position of tokens within entities. The BIO system, an acronym for Beginning, Inside, and Outside, is the most commonly employed tagging system [55]. To illustrate, in the BIO format, “B” signifies that the word marks the beginning of the entity, “I” denotes that the word is within the entity but not at the start, and “O” indicates that the word does not belong to an entity. In this context, the NER task is centered on token classification, using data that have been labeled through sequence models functioning within a multiple-input, multiple-output system. Tagging systems also prove beneficial in identifying informative labels and understanding their meaning in related contexts.
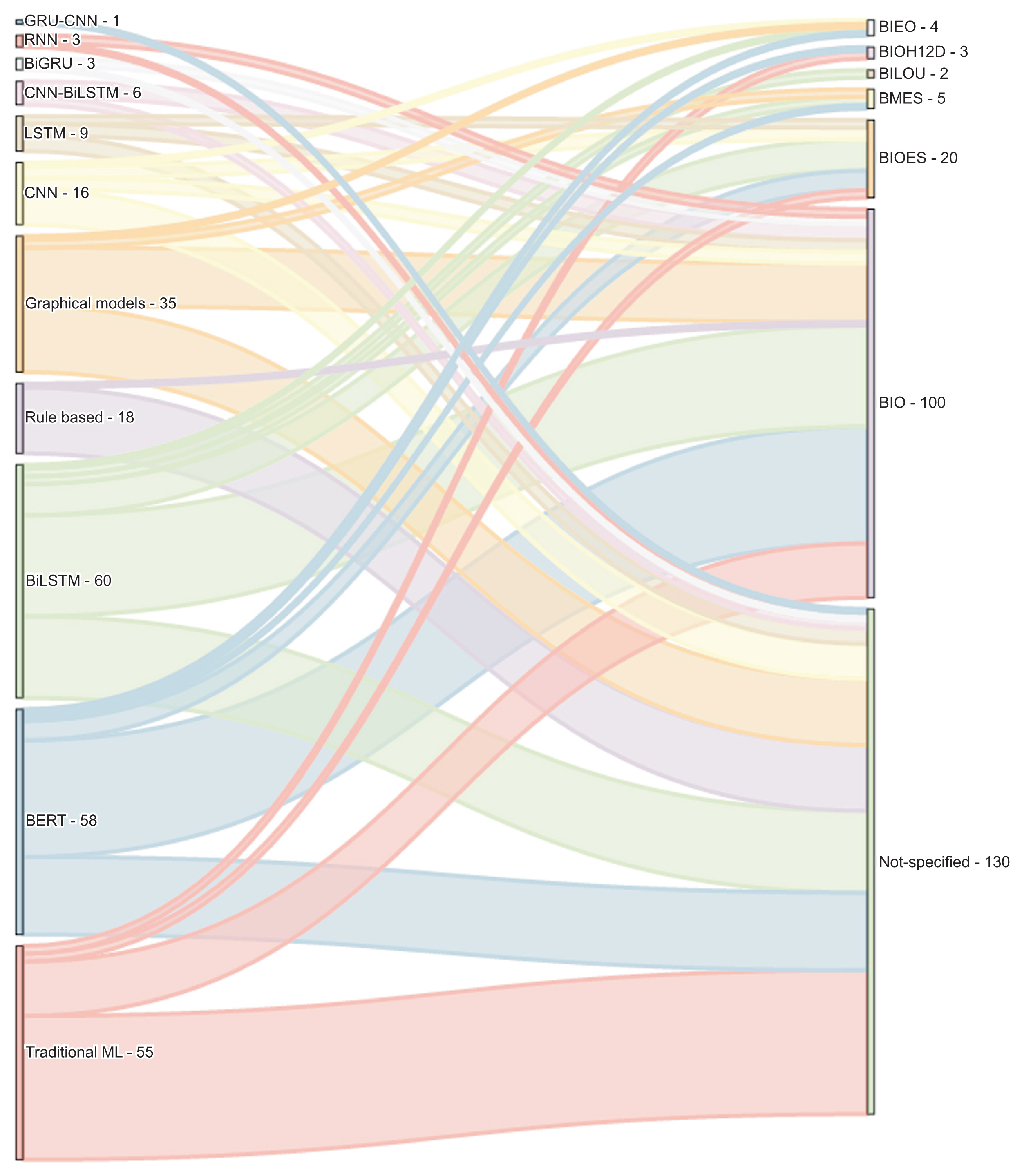
Named entity recognition approaches and types of tagging. GRU: gated recurrent unit, BiGUR: bidirectional gated recurrent unit, CNN: convolutional neural network, RNN: recurrent neural network, LSTM: long short-term memory, BiLSTM: bidirectional long short-term memory, ML: machine learning.
Only a handful of studies have employed the BIESO or BIOES format. In this context, “B” stands for “begin,” “I” for “inside,” “E” for “end,” “S” for “single,” and “O” for “outside” or not an entity. An instance of the BIOES format is documented in a study where the researchers combined the attention mechanism with a deep learning methodology to suggest an enhanced clinical NER method for Chinese EHRs [3]. For this purpose, they identified five categories of entities: anatomical part, symptom, description, independent symptom, drug, and operation. In a similar vein, another tagging system, known as BILOU, has been employed in recent studies, including [64]. In this system, “B” signifies “begin,” “I” stands for “inside,” “L” for “last,” “O” for “outside,” and “U” for “unit.”
We observed that most of the articles did not specify the tagging system, a detail that is crucial for reproducing results, particularly with deep learning classifiers. This omission is more frequently seen in rule-based and traditional machine learning classifiers, as their goal is to classify each token on an individual basis. Conversely, graphical models and deep learning methods utilize context for token classification. Therefore, when an entity is defined by two or more tokens, it becomes necessary to specify the type of tagging system used.
Figure 4 presents a graph that categorizes the articles based on language, classification methods, and tagging systems. Deep learning models were predominantly used for the NER task, accounting for 58.86% of the methods, followed by traditional machine learning methods at 20.75%, graphical models at 13.20%, and rule-based approaches at 6.79%. In terms of languages, English was the most common, representing 51.69% of the articles, followed by Chinese at 32.45%, Spanish and Swedish each at 4.15%, and Italian at 2.26%. We observed that 49.05% of the articles did not specify the tagging system, while 37.73% used BIO, and 7.54% used BIOES. It is noteworthy that deep learning approaches were adopted in 40 papers with Chinese corpora and 40 with English corpora.
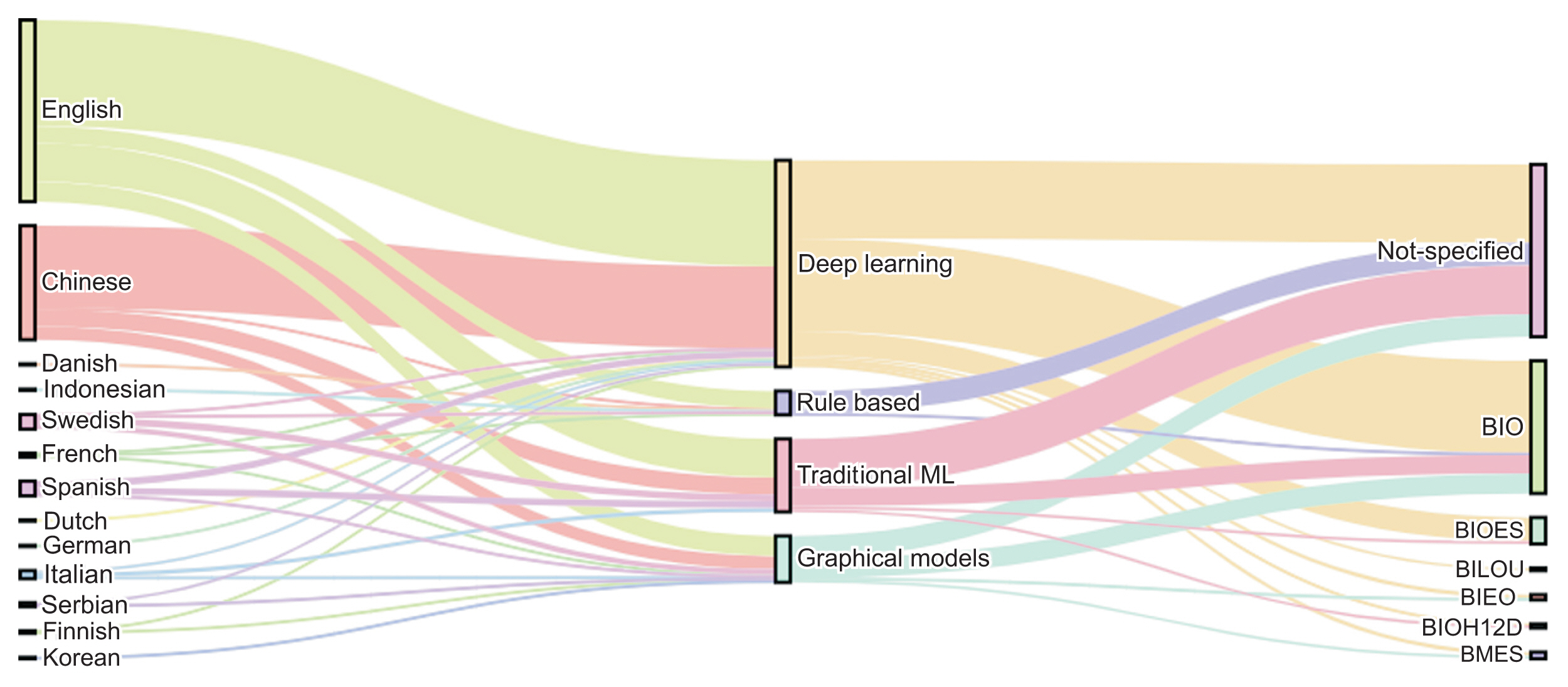
Corpus languages, types of models, and named entity recognition targets. ML: machine learning.
3. Comparison between Shared-task Corpora and Private Corpora
In this section, we analyzed the corpora reported in the literature, which were either extracted from shared tasks or are publicly accessible (refer to Table 1). The most frequently encountered shared-task dataset in our review was the 2012 i2b2 challenge, which emphasized the extraction of concepts and relations from clinical texts [8,10,23,50,88,89]. This challenge targeted the following elements: (1) Clinically relevant concepts, which include problems, tests, treatments, and clinical departments, as well as events such as admissions or transfers between departments that are pertinent to the patient’s clinical timeline. (2) Temporal expressions that denote dates, times, durations, or frequencies within the clinical text. (3) Temporal relations between clinical events and temporal expressions. The best F1-score in this challenge was attained by a hybrid NLP system that merged a rule-based method with a machine learning approach, achieving an F1-score of 0.876 in the extraction of temporal expressions [90]. This underscores that the application of sophisticated NLP techniques can significantly enhance the identification and extraction of information from clinical data.

Challenges in natural language processing
Another popular competition in the context of NLP tasks was the CCKS2017 challenge [6,35,91–94]. This challenge incorporated a dataset of 1,596 manually labeled medical records. The primary task involved the extraction of various entity types, including disease, anatomy, symptom, check, and treatment. The most successful results were obtained through the use of a straightforward CNN attention mechanism, which achieved an F1-score of 90.34% [6].
The n2c2 challenge was designed to extract adverse drug events (ADEs) from a vast quantity of unstructured clinical records [50,54,78,84,85,94]. The annotations typically encompassed a variety of entity types, such as the drug, its strength, dosage, duration, frequency, form, route of administration, the reason for its prescription, and any ADEs. The data for the 2018 n2c2 challenge were derived from discharge summaries in the MIMIC-III database. One of the most notable results that year was reported in a study where a deep learning-based approach using BiLSTM-CRF was developed, resulting in an F1-score of 92% [84].
The eHealth-KD was an NLP challenge designed to model human language within Spanish EHRs. This challenge included NER and RE tasks within a general health domain [31,42]. The datasets utilized in this challenge identified the following entity types: concept, action, reference, and negation. Furthermore, the relation types included: part-of, property-of, same-as, subject, and target. A hybrid model that combined BiLSTM-CRF and CNN was applied to this corpus, achieving an F1-score of 80.30% [31].
In regard to private corpora, this study found that only approximately 7% of the evaluated papers utilized their own unique private datasets. These datasets necessitate exclusive licenses or permissions from external sources for data access. The use of private corpora is subject to stringent confidentiality requirements; thus, they are not freely accessible [95]. Nevertheless, the employment of private corpora facilitates more thorough and contextually pertinent examinations of medical texts. This contributes to the advancement of sophisticated healthcare applications and enhances patient outcomes. Table 2 presents a selection of studies that utilized private corpora and reported F1-scores exceeding 0.75. Most private corpora were customized to cater to specific domains, such as oncology or pathology. The types of notes included in these corpora encompassed pathology reports, admission notes, and medical notes from the intensive care unit.
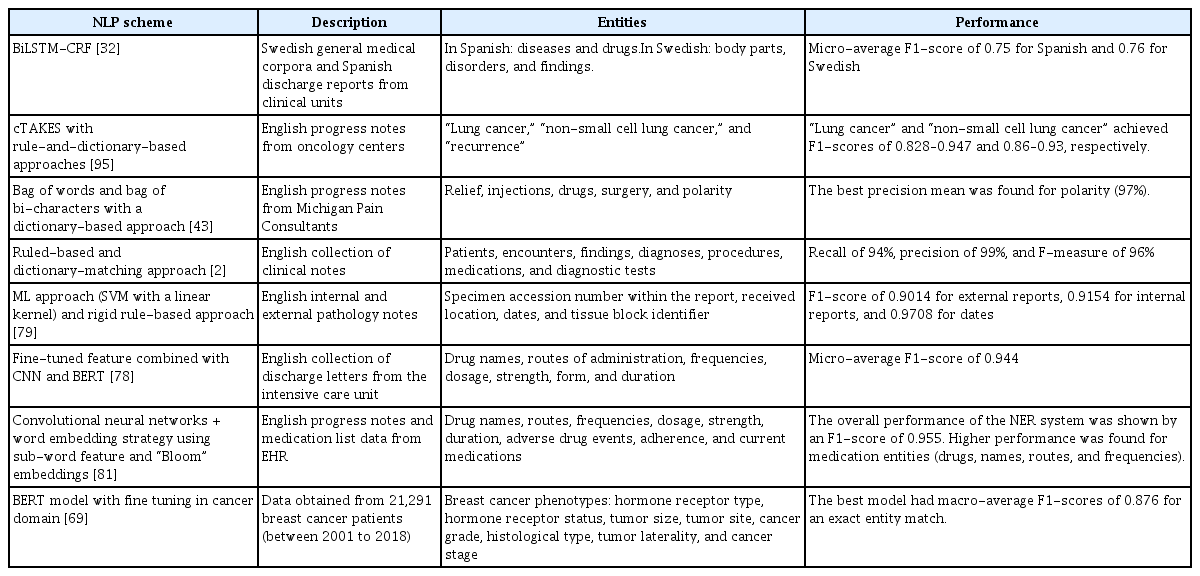
Summary of the papers utilizing a private corpus and attaining an F1-score greater than 0.75
Creating new corpora is a labor-intensive and resource-heavy task; however, it becomes essential when there is a need to develop more specialized applications [96]. The findings of this review indicate that the use of so-called public corpora is the dominant trend in publications related to NER.
4. Relation Extraction
RE is an active area of research in numerous specialized clinical fields. In this review, only three of the selected articles addressed the issue of RE, as shown in Table 3. Within the realm of medical records, we identified only two public corpora that included relation labeling: the 2010 i2b2 and the 2018 n2c2. Additionally, we discovered one article that utilized a private corpus for RE in the Chinese language [52]. It is evident that RE has not been as extensively explored as NER. Furthermore, the types of relations typically need to be defined based on the clinical domain or the entity type, adding a layer of complexity to this task that surpasses that of NER [96].
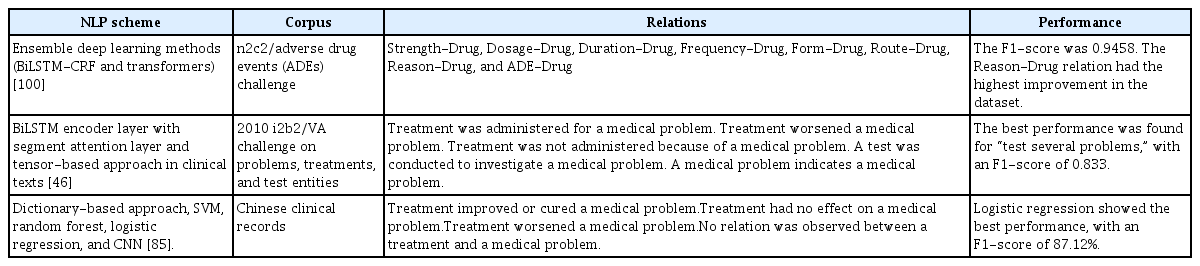
Summary of the papers reporting on RE
IV. Discussion
In this review, we found that the state-of-the-art has progressed from rule-based and traditional machine learning methods to deep-learning models over the past decade. This shift is due to the fact that the latter can comprehend the context and enhance performance beyond what the former can achieve.
The review is limited by the current lack of a universally accepted standard method for assessing the quality of NER models. For example, while the F1-score is the most common metric, some papers do not clearly specify whether they are reporting the macro-average or the micro-average F1-score. Some papers even report different metrics altogether. Similarly, some papers do not clearly state the type of tagging system they employ. We recommend that researchers, when reporting NER results, provide explicit details about the corpus, the tagging system, and the performance metrics used in their study.
In terms of tagging systems, the BIO scheme is most frequently reported, particularly in studies employing deep-learning models. The introduction of more complex tagging schemes augments the number of classes that the model is required to predict, which could potentially impact its performance.
We have noted that recent progress in this field is largely dependent on publicly accessible corpora and datasets associated with challenges. Consequently, there is a conspicuous absence of research involving actual EHRs, and a substantial gap in thorough external validation, both with respect to fresh data and real-world applications. Therefore, the creation of new corpora is essential to facilitate the swift development of NER and RE models applicable to EHRs for use in clinical practice, and to validate the outcomes in various datasets. Furthermore, initiatives should be undertaken to convert private corpora into public ones.
Most of the existing corpora utilize EHRs written in English. Additionally, we have observed a swift expansion of corpora in the Chinese language, primarily employing deep-learning models. The creation of new models in various languages presents a challenge for the global implementation of NER in clinical practice. Likewise, when dealing with languages other than English, only a few corpora are freely accessible, which underscores the importance of developing custom datasets. This is crucial to guarantee the relevance and effectiveness of NLP models in a variety of linguistic contexts.
In the realm of clinical domains, there is a scarcity of studies linked to specific medical specialties. A mere 8.13% of the studies concentrated on neoplasms, while 6.5% focused on cardiovascular diseases, 1.62% on factors influencing health status, and a scant 0.813% on mental and behavioral disorders. Most studies targeting specific domains utilized private corpora, underscoring the role of these resources in supplementing the use of public datasets. This heavy reliance on private corpora emphasizes the necessity for researchers to forge partnerships or collaborations with healthcare institutions or data providers. This allows secure access to these invaluable resources, while maintaining adherence to ethical and legal considerations to protect sensitive patient information.
As of December 2022, the most advanced models in clinical NER are those based on BERT, which undergo a fine-tuning or training stage using a domain-specific corpus. For example, models such as BioBERT, BioClinicalBERT, and BlueBERT have demonstrated superior performance in this field. In 2023, ChatGPT gained recognition for leading a revolution in the field of NLP, with notable performance on generic text corpora. However, a study conducted by Hu et al. revealed that the performance of ChatGPT, for the NER task defined in the 2010 i2b2 challenge, was inferior to that of the BioClinicalBERT model [97]. The latter model underwent a fine-tuning stage using a specific corpus. This finding aligns with the study conducted by Li et al. [98], which discovered that ChatGPT and GPT-4 encountered difficulties in areas requiring domain-specific knowledge. Specifically, they utilized financial textual datasets. Furthermore, Lai et al. [99] proposed that, for the time being, it is more practical to employ task-specific models for domain-specific tasks rather than using ChatGPT. Nevertheless, future research should be conducted to investigate the potential use of new developments in LLM for classifying named entities in EHRs.
Acknowledgments
This work was funded by the Instituto Tecnológico Metropolitano through the project (No. P20242). Also, the project received funds from the Agencia de Educación Superior de Medellín (Sapiencia).
Notes
Conflict of Interest
No potential conflict of interest relevant to this article was reported.
